6 Designing Access with Differential Privacy
Alexandra Wood (Harvard University)Micah Altman (Massachusetts Institute of Technology)
Kobbi Nissim (Georgetown University)
Salil Vadhan (Harvard University)
6.1 Introduction and Overview
This chapter explains how administrative data containing personal information can be collected, analyzed, and published in a way that ensures the individuals in the data will be afforded the strong protections of differential privacy.
It is intended as a practical resource for government agencies and research organizations interested in exploring the possibility of implementing tools for differentially private data sharing and analysis. Using intuitive examples rather than the mathematical formalism used in other guides, this chapter introduces the differential privacy definition and the risks it was developed to address. The text employs modern privacy frameworks to explain how to determine whether the use of differential privacy is an appropriate solution in a given setting. It also discusses the design considerations one should take into account when implementing differential privacy. This discussion incorporates a review of real-world implementations, including tools designed for tiered access systems combining differential privacy with other disclosure controls presented in this Handbook, such as consent mechanisms, data use agreements, and secure environments.
Differential privacy technology has passed a preliminary transition from being the subject of academic work to initial implementations by large organizations and high-tech companies that have the expertise to develop and implement customized differentially private methods. With a growing collection of software packages for generating differentially private releases from summary statistics to machine learning models, differential privacy is now transitioning to being usable more widely and by smaller organizations.
6.1.1 Organization of this Chapter
We place differential privacy in a general framework—introduced by Altman et al. (2015) and an alternative to the Five Safes framework (Desai, Ritchie, and Welpton 2016) used throughout this Handbook—that involves selecting combinations of statistical, technical, and administrative controls to mitigate risks of harm to individuals resulting from access to data. The framework discusses differential privacy as an approach to employ together with other tools, including consent mechanisms, data use agreements, and secure environments.
The chapter is organized as follows: Section 6.2 explains the differential privacy guarantee in more detail using stories to illustrate what differential privacy does and does not protect. Section 6.3 places differential privacy in a general framework of complementary privacy controls and characterizes principles for selecting differential privacy in conjunction with other controls. These principles include calibrating privacy and security controls to the intended uses and privacy risks associated with the data, and anticipating, regulating, monitoring, and reviewing interactions with data across all stages of the lifecycle (including the post-access stages), as risks and methods will evolve over time. Section 6.4 presents succinct summaries of several deployment cases. These provide selected concrete examples of data dissemination that illustrate some key design choices and their implications. Some of the content in this chapter (Sections 6.1–6.3) is excerpted from, adapted from, or otherwise based, in part, on Wood et al. (2018) and Altman et al. (2015).
More technical discussions of several topics are included in an extensive online appendix. A discussion of different technical approaches to disseminating data with differential privacy can be found in Appendix A, which also characterizes the key design choices and trade-offs across them. Appendix B elaborates on the implications of differential privacy for data collection, use, and dissemination with a special emphasis on how differential privacy affects data collection and data repository practice and policy. Appendix C provides a list of selected tools and resources for implementing differential privacy protections.
Section 6.2 is recommended for policymakers as well as for analysts and communications professionals seeking to explain differential privacy to policymakers, data users, and data subjects. Sections 6.3 and 6.4, in combination with Appendix B, are recommended for organizational directors and principal investigators responsible for identifying where differential privacy is appropriate as part of a project or organization-level data-protection strategy. Appendices A, B, and C are recommended for those with a technical background aiming to design and deploy differential privacy addressing specific data dissemination requirements.
6.1.2 Motivation: Formal Guarantees are Needed to Protect Data against Growing Privacy Risks
Government agencies and research organizations are utilizing increasingly greater quantities of personal information about individuals over progressively longer periods of time. Powerful analytical capabilities, including emerging machine learning techniques, are enabling the mining of large-scale data sets to infer new insights about human characteristics and behaviors and driving demand for large-scale data sets for scientific inquiry, public policy, and innovation. These factors are also creating heightened risks to individual privacy.
A number of measures have been developed for sharing sensitive data while protecting the privacy of individuals. These interventions encompass a wide range of legal, procedural, and technical controls, from providing access to only trusted researchers, using data enclaves, and imposing restrictions as part of data use agreements, among others. One category of controls is a collection of statistical disclosure limitation (SDL) techniques, which are widely adopted by statistical agencies, research organizations, and data analysts to analyze and share data containing privacy-sensitive information with the aim of preventing users of the data from learning personal information pertaining to an individual. Statistical disclosure limitation encompasses a wide range of methods for suppressing, aggregating, perturbing, swapping, and generalizing attributes of individuals in the data.81 SDL techniques are often applied with the explicit goal of de-identification (i.e., redacting or coarsening data with the goal of increasing the difficulty of linking an identified person to a record in a data release).82
Differential privacy is motivated by an ever-growing number of real-world examples of data releases that were thought to be sufficiently protective of privacy but were later shown to carry significant privacy risks. Over time, changes in the way information is collected and analyzed, including advances in analytical capabilities, increases in computational power, and the expanding availability of personal data from a wide range of sources, are eroding the effectiveness of traditional SDL techniques.
For over a century,83 statistical agencies have recognized the need to protect against uses of data that would threaten privacy, and, for most of this time, the primary focus of formal protections has been to prevent re-identification (for an overview, see Willenborg and De Waal 1996). Re-identification attacks gained renewed attention in the privacy research literature in the late 1990s (Sweeney 1997) and have become increasingly sophisticated over time, along with other emerging types of attacks that seek to infer characteristics of individuals based on information about them in the data (Narayanan and Shmatikov 2008; de Montjoye et al. 2013; Calandrino et al. 2011). In particular, successful attacks on de-identified data have shown that traditional technical measures for privacy protection may be vulnerable to attacks devised after a technique’s deployment and use. Some de-identification techniques, for example, categorize attributes in the data as (quasi-)identifying (e.g., names, dates of birth, or addresses) or non-identifying (e.g., movie ratings or hospital admission dates). Data providers may later discover that attributes initially believed to be non-identifying can in fact be used to re-identify individuals. De-identification hence requires a careful analysis—not only of present data sources that could be linked with the de-identified data toward enabling re-identification but also of future data sources and other hard-to-anticipate future sources of auxiliary information that can be used for re-identification.
Moreover, there are privacy attacks beyond record linkage attacks on de-identified records. A recent example illustrating the evolving nature of privacy attacks is the reconstruction and re-identification of the 2010 Decennial Census database. This example demonstrates that even publications of statistical tables transformed using traditional statistical disclosure limitation techniques may be vulnerable to privacy attacks.84
In a paper published in 2018, researchers revealed that the underlying confidential data from the 2010 US Decennial Census could be reconstructed using only the statistical tables published by the US Census Bureau (Garfinkel, Abowd, and Martindale 2019). Researchers demonstrated a type of attack, called a database reconstruction attack, that leveraged the large volumes of data from the published statistical tables in order to narrow down the possible values of individual-level records. The researchers were able to reconstruct with perfect accuracy the sex, age, race, ethnicity, and fine-grained geographic location (to the block-level) reported by Census respondents for 46 percent of the US population (J. Abowd 2019). Researchers also showed that, if they slightly relaxed their conditions and allowed age to vary by up to only one year, these five pieces of information could be reconstructed for 71 percent of the population (J. Abowd 2019).
Further, the researchers showed that the reconstructed records could be completely re-identified. They were able to assign personally identifiable information to individual records using commercial databases that were available in 2010 (J. Abowd 2019). They concluded that, with this attack, they could putatively re-identify 138 million people, and they confirmed that these re-identifications were accurate for \(52\) million people, or 17 percent of the US population (J. Abowd 2019).
These findings are startling. In 2012, the last time the Census Bureau performed a simulated re-identification attack on census data sets, the re-identification rate was only 0.0038 percent (Ramachandran et al. 2012). The test attack using the data published for the 2010 Decennial Census demonstrates that previous risk assessments underestimated the re-identification risk by a factor of at least 4,500 (Ramachandran et al. 2012).The demonstration of a database reconstruction attack on the statistical tables published by the Census Bureau is just the latest in a long line of attacks illustrating the privacy risks associated with releasing and analyzing large volumes of data about individuals. In particular, it is a real-world manifestation of the growing risks from combining and analyzing multiple statistical releases—broadly referred to as risks from composition (Ganta, Kasiviswanathan, and Smith 2008; Fluitt et al. 2019). The modern mathematical understanding recognizes that any research output increases disclosure risk.85 Although some increases in disclosure risk may be small, they accumulate, potentially to the point of a severe privacy breach. Taken together, the outputs may enable an accurate reconstruction of large portions of the data set, as seen in the reconstruction and re-identification of the 2010 Decennial Census database.
Producing accurate statistics while protecting privacy and addressing risks from composition is a challenging problem (Dwork et al. 2016). It is a fundamental law of information that privacy risk grows with the repeated use of data, and this applies to any disclosure limitation technique. Traditional SDL techniques—such as suppression, aggregation, and generalization—often reduce accuracy and are vulnerable to privacy loss due to composition.86 A rigorous analysis of the effect of composition is important for establishing a robust and realistic understanding of how multiple statistical computations affect privacy.
Privacy attacks such as these have underscored the need for privacy technologies that are immune not only to linkage attacks but to any potential attack, including attacks that are currently unknown or unforeseen. It is now understood that risks remain even if many pieces of information are removed from a data set prior to release. Extensive external information may be available to potential attackers, such as employers, insurance companies, relatives, and friends of an individual in the data. In addition, ex post remedies, such as simply “taking the data back” when a vulnerability is discovered, are ineffective because many copies of a set of data typically exist; copies may even persist online indefinitely.87
6.1.3 Features of the Differential Privacy Guarantee
Differential privacy is a strong definition (or, in other words, a standard) of privacy in the context of statistical analysis and machine learning, protecting against the threats described above, including those of unknown attacks and cumulative loss. Tools that achieve the differential privacy standard can be used to provide broad, public access to data or data summaries in a privacy-preserving way. Used appropriately, these tools can, in some cases, also enable access to data that could not otherwise be shared due to privacy concerns and do so with a guarantee of privacy protection that substantially increases the ability of the institution to protect the individuals in the data.
With differential privacy, statements about risk are proved mathematically—rather than supported heuristically or empirically. The definition of differential privacy also has a compelling intuitive interpretation: inferring information specific to an individual from the outcome of an analysis preserving differential privacy is impossible, including whether the individual’s information was used at all.
Differential Privacy Is a Standard, Not a Single Tool
Differential privacy is a standard which many tools for analyzing sensitive personal information have been devised to satisfy. Any analysis meeting the standard provably protects its data against a wide range of privacy attacks, i.e., attempts to learn private information specific to individuals from a data release.88
Differential Privacy Is Designed for Analysis of Populations, Not Individuals
Differentially private analyses can be deployed in settings in which an analyst seeks to learn about a population. For example, when statistical estimates (such as counts, averages, histograms, contingency tables, regression coefficients, and synthetic data) are computed based on personal information, the privacy of the individuals in the data needs to be protected.
The Differential Privacy Guarantee
It is mathematically guaranteed that the recipient of a data release generated by a differentially private analysis will make essentially the same inferences about any single individual’s private information, whether or not that individual’s private information is included in the input to the analysis.
The differential privacy guarantee can be understood in reference to other privacy concepts, such as opt-out and protection of personally identifiable information (PII):
Differential privacy protects an individual’s information essentially as if their data were not used in the analysis at all (i.e., as though the individual opted out and the information was not used).
Differential privacy ensures that using an individual’s data will not reveal essentially any PII that is specific to them. Here, specific refers to information that cannot be inferred about an individual unless their information is used in the analysis. Information specific to an individual would be considered PII under a variety of interpretations.89
Differentially Private Analysis Requires the Introduction of Statistical Noise
To achieve differential privacy, carefully crafted random statistical noise must be injected into statistical and machine-learning analyses.90
Protecting Privacy Increases the Uncertainty of Results
The introduction of statistical noise to protect privacy necessarily reduces the accuracy of statistical analyses. As the number \(n\) of observations in a data set grows sufficiently large, the loss in accuracy due to differential privacy can become much smaller than other sources of error such as statistical sampling error. However, maintaining high accuracy for studies on small or modest-sized data sets (or modest-sized subsets of large data sets) is a challenge. As a consequence, all results computed using tools for differentially private analysis will be approximate. Conversely, any system that produces exact results without any random modifications cannot meet the differential privacy standard.
Preventing Cumulative Privacy Failure Requires a Budget for Privacy Loss, Which in Turn Limits Utility
Every computation leaks some information about the individual records used as input regardless of the protection method used. To prevent cumulative privacy failure, the privacy loss that accumulates over multiple computations must be calculated, tracked, and limited. Differential privacy provides explicit, formal methods for defining and managing this cumulative loss, referred to as the privacy-loss budget.
The inevitability of privacy loss implies that there is an inherent trade-off between privacy and utility as the former degrades with an increase of the latter. Formal frameworks for statistical disclosure limitation (such as differential privacy) are distinct from traditional, less formal approaches in that formal frameworks quantify this trade-off explicitly: what can be learned about an individual as a result of their private information being included in a differentially private analysis is strictly limited and quantified by a privacy loss parameter, usually denoted epsilon (\(\varepsilon\)). Further, many tools for differentially private analysis are designed to make efficient trade-offs between privacy and utility.
6.1.4 An Illustrative Scenario: Publishing Education Statistics
The scenarios in this section illustrate the types of information disclosures that are addressed when using differential privacy.
Alice and Bob are professors at Private University. They both have access to a database that contains personal information about students at the university, including information related to the financial aid each student receives. To gain access, Alice and Bob were required to undergo confidentiality training and to sign data use agreements restricting the disclosure of personal information obtained from the database.
In March, Alice publishes an article based on the information in this database and writes that “the current freshman class at Private University is made up of 3,005 students, 202 of whom are from families earning over US$350,000 per year.” Alice reasons that no individual’s personal information will be exposed because she published an aggregate statistic taken over 3,005 people. The following month, Bob publishes a separate article containing these statistics: “201 families in Private University’s freshman class of 3,004 have household incomes exceeding US$350,000 per year.” Neither Alice nor Bob is aware that they have both published similar information.
A clever student Eve reads both of these articles and makes an observation. From the published information, Eve concludes that between March and April one freshman withdrew from Private University and that the student’s parents earn over US$350,000 per year. Eve asks around and is able to determine that a student named John dropped out around the end of March. Eve then informs her classmates that John’s parents probably earn over US$350,000 per year.
John hears about this and is upset that his former classmates learned about his parents’ financial status. He complains to the university and Alice and Bob are asked to explain. In their defense, both Alice and Bob argue that they published only information that had been aggregated over a large population and does not identify any individuals.This story illustrates how the results of multiple analyses using information about the same people, when studied in combination, may enable one to draw conclusions about individuals in the data. Alice and Bob may each publish information that seems innocuous in isolation. However, when combined, the information they publish can compromise the privacy of one or more individuals. This type of privacy breach is generally difficult to prevent by Alice and Bob individually, as it is likely that neither knows what information has already been revealed or will be revealed by others in future. This problem is referred to as the problem of composition.
Suppose, instead, that the institutional review board at Private University only allows researchers to access student records by submitting queries to a special data portal, which responds to every query with an answer produced by running a differentially private computation on the student records.
This example hints at one of the most important properties of differential privacy: it is robust under composition. If multiple differentially private analyses are performed on data describing the same set of individuals, then the guarantee is that all of the information released will still be differentially private. Notice how this scenario is markedly different from the previous hypothetical in which Alice and Bob do not use differentially private analyses and inadvertently release two statistics that in combination lead to the full disclosure of John’s personal information. The use of differential privacy rules out the possibility of such a complete breach of privacy. This is because differential privacy enables one to measure and bound the cumulative privacy risk from multiple analyses of information about the same individuals.
However, every analysis, regardless of whether it is differentially private, results in some leakage of information about the individuals whose data are being analyzed, and this leakage accumulates with each analysis. This is true for every release of data, including releases of aggregate statistics. In particular, the example above should not be understood to imply that privacy does not degrade after multiple differentially private computations. In fact, as indicated in Section 6.2.4, privacy risks accumulate with each release or analysis involving an individual’s data. For this reason, there is a limit to how many analyses can be performed on a specific data set while providing an acceptable guarantee of privacy. Therefore, measuring privacy loss and understanding quantitatively how risk accumulates across successive analyses are critical. In the context of the example above, measures need to be established, such as restricting the overall number of queries to which researchers may apply to Private University’s database.
6.1.5 What Types of Analyses are Performed Using Differential Privacy
Differentially private algorithms are known to exist for a wide range of statistical analyses, such as count queries, histograms, cumulative distribution functions, and linear regression; techniques used in statistics and machine learning, such as clustering and classification; and statistical disclosure limitation techniques, like synthetic data generation, among many others.
Count Queries
Differentially private answers to count queries (i.e., estimates of the number of individual records in the data satisfying a specific condition) can be obtained through the addition of random noise (Dwork et al. 2016).
Histograms
Differentially private computations can provide noisy counts for data points classified into the disjoint categories represented in histograms or contingency tables (i.e., cross-tabulations) (Dwork et al. 2016).
Cumulative Distribution Function (CDF)
There are differentially private algorithms for estimating the entire CDF of a dataset (or the distribution from which it is drawn) (Bun et al. 2015). These algorithms introduce noise that needs to be taken into account when statistics such as median or interquartile range are computed from the estimated CDF.91
Linear Regression
Differentially private algorithms for linear regression introduce noise in a variety of different ways, and the choice of which algorithm is best will depend on properties of the underlying data distribution (e.g., the amount of variance in the explanatory variables), the sample size, the privacy parameters, and the intended application (Wang 2018; Alabi et al. 2020).
Clustering
Researchers are developing a variety of differentially private clustering algorithms (i.e., algorithms for grouping data points into clusters so that points in the same cluster are more similar to each other than to points in other clusters) (Stemmer and Kaplan 2018), and such tools are likely to be included in future privacy-preserving tool kits for exploratory analysis by social scientists.
Classification and Machine Learning
Theoretical work has shown it is possible to construct differentially private algorithms for a large collection of classification tasks, such as identifying or predicting to which set of categories a data point belongs based on a training set of examples for which category membership is known (Blum et al. 2005; Kasiviswanathan et al. 2011), and subsequent work has developed more practical methods for differentially private machine learning, including deep learning (Abadi et al. 2016).
Synthetic data generation
Research has shown that in principle it is possible to generate differentially private synthetic data that preserves a vast collection of statistical properties of the original data set.92 A significant benefit is that once a differentially private synthetic data set is generated, it can be analyzed any number of times, without any further implications for privacy. As a result, synthetic data can be shared freely or even made public in many cases. For example, statistical agencies can release synthetic microdata as public-use data files in place of raw microdata. However, significant challenges remain with respect to both the level of random noise introduced and computational efficiency for general-purpose differentially private synthetic generation in practice, particularly for high-dimensional data.93
6.2 How Differential Privacy Protects Privacy
6.2.1 What Does Differential Privacy Protect?
Intuitively, a computation protects the privacy of individuals in the data if the computational output does not reveal any information that is specific to any individual subject. Differential privacy formalizes this intuition as a mathematical definition. Similar to showing that an integer is even by proving that it is the result of multiplying some integer by two, a computation is shown to be differentially private by proving it meets the constraints of the definition. In turn, if a computation can be proven to be differentially private, one can rest assured that using the computation will not unduly reveal information specific to a data subject.
To see how differential privacy formalizes this privacy requirement as a definition, consider the following scenario.
Researchers have selected a sample of individuals across the US to participate in a survey exploring the relationship between socioeconomic status and health outcomes. The participants were asked to complete a questionnaire covering topics such as where they live, their finances, and their medical history.
One of the participants, John, is aware that individuals have been re-identified in previous releases of de-identified data and is concerned that personal information he provides about himself, such as his medical history or annual income, could one day be revealed in de-identified data released from this study. If leaked, this information could lead to an increase in his life insurance premium or an adverse decision for a future mortgage application.Differential privacy can be used to address John’s concerns. If the researchers only share data resulting from a differentially private computation, John is guaranteed that the release will not disclose anything that is specific to him even though he participated in the study.
To understand what this means, consider a thought experiment, which is illustrated in Figure 6.1 and is referred to as John’s opt-out scenario.94 In John’s opt-out scenario, an analysis is performed using data about the individuals in the study, except that information about John is omitted. His privacy is protected in the sense that the outcome of the analysis does not depend on his specific information, because it was not used in the analysis at all.
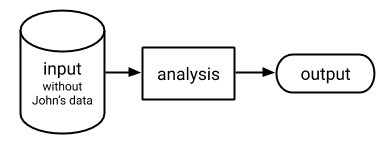
Figure 6.1: John’s opt-out scenario
John’s opt-out scenario differs from the scenario depicted in Figure 6.2, referred to as the real-world scenario, in which the analysis is based on John’s personal information along with the personal information of the other study participants. The real-world scenario involves some potential risk to John’s privacy as some of his personal information could be revealed by the outcome of the analysis, because it was used as input to the computation.
Differential privacy aims to protect John’s privacy in the real-world scenario in a way that mimics the privacy protection he is afforded in his opt-out scenario.95 Accordingly, what can be learned about John from a differentially private computation is (essentially) limited to what could be learned about him from everyone else’s data without his own data being included in the computation. Crucially, this same guarantee is made not only with respect to John but also with respect to every other individual contributing their information to the analysis.
For a precise description of differential privacy and the mathematics underlying the construction of differentially private analysis, the reader is referred to the literature listed in Further Reading. In lieu of the mathematical definition, this chapter offers a few illustrative examples to discuss various aspects of differential privacy in a way that is intuitive and generally accessible.
6.2.2 Privacy Protection is a Property of an Analysis—Not a Data Release
Throughout this chapter, we refer to the general concept of an analysis that performs a computation on input data and outputs the result (illustrated in Figure 6.2).96 The analysis may be as simple as determining the average age of the individuals in the data, or it may be more complex and utilize sophisticated modeling and inference techniques.
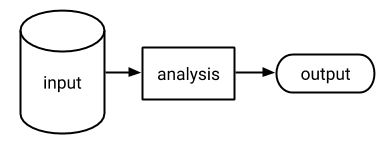
Figure 6.2: An analysis (or computation) transforms input data into some output
We focus specifically on analyses that transform sensitive personal data into an output that can be released publicly. For example, an analysis may involve the application of techniques for aggregating or de-identifying a set of personal data in order to produce a sanitized version of the data that is safe to release. How can the data provider ensure that publishing the output of this computation will not unintentionally leak information from the privacy-sensitive input data?
A key insight from the theoretical computer science literature is that privacy is a property of the informational relationship between the input and output, not a property of the output alone.97 In other words, one can be certain that the output of a computation is privacy-preserving if the computation itself is privacy-preserving. The following examples show why this is the case.
Consider the following statistic: “a representative ninth-grade GPA at City High School is 3.5.” One might naturally think that this statistic is unlikely to reveal private information about an individual student. However, one needs to know how the statistic was computed to make that determination. For instance, if the representative ninth-grade GPA was calculated by taking the GPA of the alphabetically first student in the school, then the statistic completely reveals the GPA of that student.98 Alternatively, a representative statistic could be based on average features of the ninth graders in the school—using the most common first name, the most common last name, the average age, and the average GPA to produce “John Smith, a fourteen-year-old in the ninth grade, has a 3.1 GPA.” Suppose that coincidentally a student named John Smith subsequently joins the ninth-grade class. Although his name appears in the published statistic, one knows with certainty that the statistic does not reveal private information about him, because it was not based on his student records in any way.
These examples are clearly contrived, and no reasonable analyst would publish either statistic. On a fundamental level, however, the examples demonstrate that when trying to decide whether a data release can be made public, one needs to consider the computation used to produce that release and not the release by itself. Thus, when thinking about privacy in the context of statistical releases, one should think about it as a computational property, especially if the goal is to make rigorous, formal claims about the data. This is one of the properties of differential privacy. If a computation can be proven to be differentially private, the researcher can rest assured that using the computation will not unduly reveal information specific to a data subject. Adopting this formal approach to privacy yields several practical benefits for users, including robustness to auxiliary information, composition, and post-processing, as well as transparency—each discussed in turn below in Section 6.2.3.
6.2.3 Methodology Example: Limiting Privacy Loss from Participation in Research
In the earlier example featuring Professors Alice and Bob at Private University, differentially private analyses add random noise to the statistics they produce.99 This noise masks the differences between the real-world computation and the opt-out scenario of each individual in the data set. This means that the outcome of a differentially private analysis is not exact but an approximation. In addition, a differentially private analysis may return different results, even if performed twice on the same data set. Because researchers intentionally add random noise, analyses performed with differential privacy differ from standard statistical analyses, such as the calculation of averages, medians, and linear regression equations.
Consider a differentially private analysis that computes the number of students in a sample with a GPA of at least 3.0. Say that there are 10,000 students in the sample, and exactly 5,603 of them have a GPA of at least 3.0. An analysis that added no random noise would hence report that 5,603 students had a GPA of at least 3.0.
However, a differentially private analysis adds random noise to protect the privacy of the data subjects. For instance, a differentially private analysis might report an answer of 5,521 students when run on the data; when run a second time on the same information, it might report an answer of 5,586 students.
In a differentially private analysis, the added noise makes every potential answer almost as likely whether John’s data are used in the analysis or not. This is done by controlling the likelihood ratio of any answer with John’s data included or excluded.A differentially private analysis might produce many different answers given the same data set. Because the details of a method providing differential privacy can be made public, an analyst may be able to calculate accuracy bounds that show how much an output of the analysis is expected to differ from the noiseless answer.
An essential component of a differentially private computation is the privacy loss parameter, usually denoted by the Greek letter \(\varepsilon\) (epsilon). This parameter determines how much noise is added to the computation. Choosing a value for the privacy loss parameter can be thought of as a tuning knob for balancing privacy and accuracy. A lower value for \(\varepsilon\) corresponds to stronger privacy protection and also a larger decrease in accuracy, whereas a higher value for \(\varepsilon\)corresponds to weaker privacy protection and also a smaller decrease in accuracy. The following discussion establishes an intuition for this parameter. It can be thought of as limiting how much a differentially private computation is allowed to deviate from the opt-out scenario of an individual in the data.
Consider the opt-out scenario for a certain computation, such as estimating the number of HIV-positive individuals in a surveyed population. Ideally, this estimate should remain exactly the same whether or not a single individual, such as John, is included in the survey. However, ensuring this property exactly would require the total exclusion of John’s information from the analysis. It would also require the exclusion of Gertrude’s and Peter’s information in order to provide privacy protection for them. Continuing with this line of argument, one comes to the conclusion that the personal information of every surveyed individual must be excluded in order to satisfy that individual’s opt-out scenario. Thus, the analysis cannot rely on any person’s information and is completely useless.
To avoid this dilemma, differential privacy requires only that the output of the analysis remain approximately the same whether John participates in the survey or not. Differential privacy allows for a deviation between the output of the real-world analysis and that of each individual’s opt-out scenario. The privacy loss parameter \(\varepsilon\) quantifies and limits the extent of the deviation between the opt-out and real-world scenarios, as shown in Figure 6.3 below.100 The parameter \(\varepsilon\) measures the effect of each individual’s information on the output of the analysis. It can also be viewed as a measure of the additional privacy risk an individual could incur beyond the risk incurred in the opt-out scenario.101 Note that in Figure 6.3 John has been replaced with an arbitrary individual \(X\) to emphasize that the differential privacy guarantee is made simultaneously to all individuals in the sample, not just John.
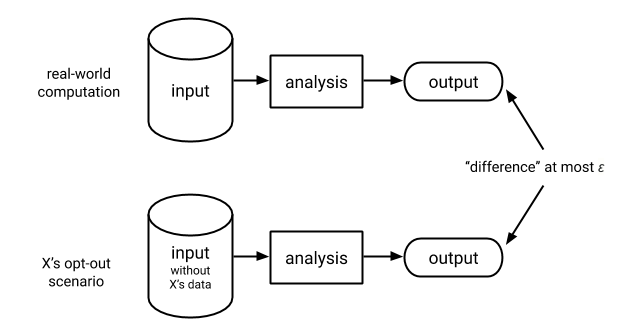
Figure 6.3: Differential privacy. The maximum deviation between the opt-out scenario and real-world computation should hold simultaneously for each individual X whose information is included in the input.
Choosing a value for \(\varepsilon\) can be thought of as tuning the level of privacy protection required. This choice also affects the utility or accuracy that can be obtained from the analysis. A smaller value of \(\varepsilon\) results in a smaller deviation between the real-world analysis and each opt-out scenario and is therefore associated with stronger privacy protection but less accuracy. For example, when \(\varepsilon\) is set to zero, the real-world differentially private analysis mimics the opt-out scenario of each individual perfectly. However, as argued at the beginning of this section, an analysis that perfectly mimics the opt-out scenario of each individual would require ignoring all information from the input and accordingly could not provide any meaningful output. Yet when \(\varepsilon\) is set to a small number, such as \(0.1\), the deviation between the real-world computation and each individual’s opt-out scenario will be small, providing strong privacy protection while also enabling an analyst to derive useful statistics based on the data.
Simple conventions for choosing \(\varepsilon\) have not yet been developed; the current best practice for choosing \(\varepsilon\) is to explore the trade-off between the choice of \(\varepsilon\) and the utility provided by an analysis for every application, as well as to consider the potential risks to individuals and the level of risk the data owner might be permitting given their legal, contractual, and ethical obligations. It is expected that as the use of differentially private analyses in real-life applications increases, the accumulated experience will shed light on how to reach a reasonable compromise between privacy and accuracy. As a rule of thumb, however, \(\varepsilon\) should be thought of as a small number, between approximately \(1/100\) and \(1\).102
This chapter has discussed how the privacy loss parameter limits the deviation between the real-world computation and each data subject’s opt-out scenario. However, it might not be clear how this abstract guarantee relates to privacy concerns in the real world. Therefore, in this section, a practical interpretation of the privacy loss parameter is discussed as a bound on the financial risk incurred by participating in a study.
Any useful analysis carries the risk that it will reveal information about individuals (which in turn might result in a financial cost). The following example shows that while differential privacy necessarily cannot eliminate this risk, it can guarantee that the risk will be limited by quantitative bounds that depend on \(\varepsilon\).
Gertrude, a 65-year-old woman, is considering whether to participate in a medical research study. While she can envision many potential personal and societal benefits resulting from her participation in the study, she is concerned that the personal information she discloses over the course of the study could lead to an increase in her life insurance premium.
For example, Gertrude is apprehensive that the tests she would undergo as part of the research study would reveal that she is predisposed to suffer a stroke and is significantly more likely to die in the coming year than the average person of her age and gender. If such information related to Gertrude’s increased risk of morbidity and mortality is discovered by her life insurance company, it will likely increase her premium substantially.
Before she decides to participate in the study, Gertrude wishes to be assured that privacy measures are in place to ensure that her involvement will have a limited effect (if any) on her life insurance premium.Gertrude’s life insurance company may raise her premium based on something it learns from the medical research study, even if Gertrude does not herself participate in the study. The following example is provided to illustrate such a scenario.103
Gertrude holds a US$100,000 life insurance policy. Her life insurance company has set her annual premium at US$1,000 (i.e., 1 percent of US$100,000) based on actuarial tables that show that someone of Gertrude’s age and gender has a 1 percent chance of dying in the next year.
Suppose Gertrude opts out of participating in the medical research study. Regardless, the study reveals that coffee drinkers are more likely to suffer a stroke than non-coffee drinkers. Gertrude’s life insurance company may update its assessment and conclude that as a 65-year-old woman who drinks coffee, Gertrude has a 2 percent chance of dying in the next year. The insurance company decides to increase Gertrude’s annual premium from US$1,000 to US$2,000 based on the findings of the study.In this hypothetical example, the results of the study led to an increase in Gertrude’s life insurance premium, even though she did not contribute any personal information to the study. A potential increase of this nature is likely unavoidable to Gertrude because she cannot prevent other people from participating in the study. This type of effect is taken into account by Gertrude’s insurance premium in her opt-out scenario and will not be protected against by differential privacy.
Next, consider the increase in risk that is due to Gertrude’s participation in the study.
Suppose Gertrude decides to participate in the research study. Based on the results of medical tests performed on Gertrude over the course of the study, the researchers conclude that Gertrude has a 50 percent chance of dying from a stroke in the next year. If the data from the study were to be made available to Gertrude’s insurance company, it might decide to increase her insurance premium from US$2,000 to more than US$50,000 in light of this discovery.
Fortunately for Gertrude, this does not happen. Rather than releasing the full data set from the study, the researchers release only a differentially private summary of the data they collected. Differential privacy guarantees that if the researchers use a value of \(\varepsilon = 0.01\), then the insurance company’s estimate of the probability that Gertrude will die in the next year can increase from 2 percent to at most 2.04 percent, as per the equation:
Thus, Gertrude’s insurance premium can increase from US$2,000 to US$2,040, at most. Gertrude’s first-year cost of participating in the research study in terms of a potential increase in her insurance premium is at most US$40.
Note that this analysis does not imply that the insurance company’s estimate of the probability that Gertrude will die in the next year must increase as a result of her participation in the study, nor that if the estimate increases it must increase to 2.04 percent. What the analysis shows is that if the estimate were to increase, it would not exceed 2.04 percent.
Consequently, this analysis does not imply that Gertrude would incur an increase in her insurance premium or that if she were to see such an increase it would cost her US$40. What is guaranteed is that if Gertrude should see an increase in her premium, this increase would not exceed US$40.Gertrude may decide that the potential cost of participating in the research study, US$40, is too high and she cannot afford to participate with this value of \(\varepsilon\) and this level of risk. Alternatively, she may decide that it is worthwhile. Perhaps she is paid more than US$40 to participate in the study or the information she learns from the study is worth more than US$40 to her. The key point is that differential privacy allows Gertrude to make a more informed decision based on the worst-case cost of her participation in the study.
It is worth noting that should Gertrude decide to participate in the study, her risk might increase even if her insurance company is not aware of her participation. For instance, the study might determine that Gertrude has a very high chance of dying next year, and that could affect the study results. In turn, her insurance company might decide to raise her premium, because she fits the profile of the studied population (even if the company does not believe her data were included in the study). On the other hand, differential privacy guarantees that even if the insurance company knows that Gertrude did participate in the study, it can essentially only make inferences about her that it could have made if she had not participated in the study.
One can generalize from Gertrude’s scenario and view differential privacy as a framework for reasoning about the increased risk that is incurred when an individual’s information is included in a data analysis. Differential privacy guarantees that an individual will be exposed to essentially the same privacy risk regardless of whether their data are included in a differentially private analysis. In this context, think of the privacy risk associated with a data release as the potential harm that an individual might experience due to a belief that an observer forms based on that data release.
In particular, when \(\varepsilon\) is set to a small value, the probability that an observer will make some inference that is harmful to a data subject based on a differentially private data release is no greater than \(1 + \varepsilon\) times the probability that the observer would have made that inference without the data subject’s inclusion in the data set.105 For example, if \(\varepsilon\) is set to 0.01, then the probability of any adverse event to an individual (such as Gertrude being denied insurance) can grow by a multiplicative factor of 1.01 (at most) as a result from participation in a differentially private computation (compared with not participating in the computation).
As shown in the Gertrude scenario, there is also the risk to Gertrude that the insurance company will see the study results, update its beliefs about the mortality of Gertrude, and charge her a higher premium. If the insurance company infers from the study results that Gertrude has probability \(p\) of dying in the next year, and her insurance policy is valued at US$ 100,000, this translates into a risk (in financial terms) of a higher premium of \(p \times\) US$ 100,000. This risk exists even if Gertrude does not participate in the study. Recall how in the first hypothetical, the insurance company’s belief that Gertrude will die in the next year doubles from 1 percent to 2 percent, increasing her premium from US$1,000 to US$2,000, based on general information learned from the individuals who did participate. Also, if Gertrude does decide to participate in the study (as in the second hypothetical), differential privacy limits the change in this risk relative to her opt-out scenario. In financial terms, her risk increases by US$40 at most, since it can be shown that the insurance company’s beliefs about her probability of death change from 2 percent to no greater than \(2\% \cdot (1 + 2 \cdot \varepsilon) = 2.04\%\), when \(\varepsilon = 0.01\).106
Note that the above calculation requires certain information that may be difficult to determine in the real world. In particular, the 2 percent baseline in Gertrude’s opt-out scenario (i.e., Gertrude’s insurer’s belief about her chance of dying in the next year) is dependent on the results from the medical research study, which Gertrude does not know at the time she makes her decision whether to participate. Fortunately, differential privacy provides guarantees relative to every baseline risk.
Calculations like those used in the analysis of Gertrude’s privacy risk can be performed by referring to Table 6.1.107 For example, the value of \(\varepsilon\) used in the research study in which Gertrude considered participating was 0.01, and the baseline privacy risk in her opt-out scenario was 2 percent. As shown in Table 6.1, these values correspond to a worst-case privacy risk of 2.04 percent in her real-world scenario. Notice also how the calculation of risk would change with different values. For example, if the privacy risk in Gertrude’s opt-out scenario were 5 percent rather than 2 percent and the value of epsilon remained the same, then the worst-case privacy risk in her real-world scenario would be 5 percent.
| posterior belief given \(A(x')\) in % | 0.01 | 0.05 | 0.1 | 0.2 | 0.5 | 1 |
|---|---|---|---|---|---|---|
| 0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1 | 1.02 | 1.11 | 1.22 | 1.49 | 2.72 | 7.39 |
| 2 | 2.04 | 2.21 | 2.44 | 2.98 | 5.44 | 14.78 |
| 3 | 3.06 | 3.32 | 3.66 | 4.48 | 8.15 | 22.17 |
| 5 | 5.10 | 5.53 | 6.11 | 7.46 | 13.59 | 36.95 |
| 10 | 10.20 | 11.05 | 12.21 | 14.92 | 27.18 | 73.89 |
| 25 | 25.51 | 27.63 | 30.54 | 37.30 | 67.96 | 89.85 |
| 50 | 50.99 | 54.76 | 59.06 | 66.48 | 81.61 | 93.23 |
| 75 | 75.50 | 77.38 | 79.53 | 83.24 | 90.80 | 96.62 |
| 90 | 90.20 | 90.95 | 91.81 | 93.30 | 96.32 | 98.65 |
| 95 | 95.10 | 95.48 | 95.91 | 96.65 | 98.16 | 99.32 |
| 98 | 98.04 | 98.19 | 98.36 | 98.66 | 99.26 | 99.73 |
| 99 | 99.02 | 99.10 | 99.18 | 99.33 | 99.63 | 99.86 |
| 100 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| For each value of \(\varepsilon\), maximum posterior belief given A(x) in % |
The fact that the differential privacy guarantee applies to every privacy risk means that Gertrude can know for certain how participating in the study might increase her risks relative to opting out, even if she does not know a priori all the privacy risks posed by the data release. This enables Gertrude to make a more informed decision about whether to take part in the study. For instance, she can calculate how much additional risk she might incur by participating in the study over a range of possible baseline risk values and decide whether she is comfortable with taking on the risks entailed by these different scenarios.
6.2.4 Strengths of Differential Privacy Over Traditional SDL Approaches
This discussion outlines some of the key features of differential privacy that enable it to overcome the weaknesses of traditional approaches and provide strong protection against a wide range of privacy attacks.
Differential Privacy is Robust to Auxiliary Information
As illustrated by the re-identification attack on the 2010 Decennial Census database described in Section 6.1.2, effective privacy protection requires taking auxiliary information into account. A data provider designing a differentially private data release need not anticipate particular types of privacy attacks, such as the likelihood that one could link particular fields with other data sources that may be available. When using differential privacy, even an attacker utilizing arbitrary auxiliary information cannot learn much more about an individual in a database than they could if that individual’s information were not in the database at all.
Currently, differential privacy is the only framework that provides meaningful privacy guarantees in scenarios in which adversaries have access to arbitrary external information. Releases constructed in a differentially private manner provide provable privacy protection against any feasible adversarial attack, whereas de-identification concepts only counter a limited set of specific attacks.
Differential Privacy is Robust to Composition
When evaluating privacy risk, it is important to recognize that privacy risk accumulates with each release or analysis involving an individual’s data. Under what has come to be called the fundamental law of information recovery, releasing “overly accurate answers to too many questions will destroy privacy in a spectacular way” (Dinur and Nissim 2003; Dwork et al. 2017; Dwork and Roth 2014). This is true whether or not any privacy-preserving technique is applied and regardless of the specific privacy-preserving technique in use.108 A reconstruction attack, such as the reconstruction of the 2010 Decennial Census database presented in Section 6.1.2, is an example of a privacy attack that leveraged composition.
One of the most powerful features of differential privacy is its robustness under composition; in other words, the combination of multiple differentially private analyses preserves differential privacy (Dwork et al. 2016; Ganta, Kasiviswanathan, and Smith 2008). Differential privacy provides provable bounds with respect to the cumulative risk from multiple data releases, and is the only existing approach to do so. Recall that the definition of differential privacy is equipped with a numeric parameter \(\varepsilon >\) 0 that bounds privacy risk.109 Furthermore, one can reason about—and bound—the overall privacy risk that accumulates when multiple differentially private computations are performed on an individual’s data. As a simple example, imagine that two differentially private computations are performed on data sets containing information about the same individuals. If \(\varepsilon_{1}\) bounds the privacy risk of the first computation and \(\varepsilon_{2}\) bounds the privacy risk of the second computation, then the cumulative privacy risk resulting from these computations is no greater than the risk associated with an aggregate parameter of \(\varepsilon_{1} + \varepsilon_{2}\). In other words, the composition of the two differentially private analyses is also a differentially private analysis with privacy risk at most \(\varepsilon_{1} + \varepsilon_{2}\). Importantly, no coordination is needed between the two mechanisms for this bound to hold.
The example above is a simple instance illustrating how analysts can bound the total disclosure risk due to multiple differentially private disclosures. Often, better bounds can be achieved via applying a set of tools known as composition theorems. The fact that the total disclosure risk can be bounded—without having mechanisms coordinate their actions—allows for a rigorous management of privacy risks across multiple disclosures and access points. As an example, a registry such as the Epsilon Registry suggested by Dwork, Kohli, and Mulligan (2019) can hold information about the value of the privacy parameter \(\varepsilon\) used in implementations of differentially private data releases and hence serve as a basis for bounding the total disclosure risk.110
Differential Privacy is Robust to Post-Processing
It is also important to evaluate whether an approach to privacy that is being considered can be made ineffective through post-processing, i.e., via further analyzing a data release that purports to preserve privacy. For example, Machanavajjhala and Kifer (2015) describe post-processing vulnerabilities for some algorithms that satisfy k-anonymity. The demonstration of a reconstruction attack on the 2010 Decennial Census database presented in Section 6.1.2 is an example of a privacy attack that employed post-processing: while the released data tables purportedly preserved privacy, analyzing the releases enabled the reconstruction of individual respondents’ records.
Differential privacy is an example of an approach that is robust to post-processing. To understand what this means, consider a scenario in which an analyst applies a post-processing transformation \(B\) on the output of the \(\varepsilon\)-differentially private analysis \(A\). For instance, after a data publisher adds noise to a collection of statistics using a differentially private tool, they might wish to round the statistics or replace negative statistics with zero before publishing them. In such cases, the resulting analysis (\(B \circ A\)) is also \(\varepsilon\)-differentially the risk to privacy. A data publisher can even share details about the analysis \(A\), the transformation \(B\), and the value of \(\varepsilon\) without increasing privacy risk. Importantly, the guarantee that (\(B \circ A\)) is \(\varepsilon\)-differentially private holds for any transformation \(B\)—even one that is designed with an intention to breach privacy.
Differential Privacy Does Not Rely on Security by Obscurity
Differentially private tools also have the benefit of transparency, as maintaining secrecy around a differentially private computation or its parameters is not necessary. This feature distinguishes differentially private tools from traditional de-identification techniques, which often require concealment of the extent to which the data have been transformed and thereby leave data users with uncertainty regarding the accuracy of analyses on the data. This approach can enable public scrutiny of the privacy-preserving techniques used. Further, the amount of noise added by differential privacy can be taken into account in the measure of accuracy, unlike traditional techniques that keep the information needed to estimate the privacy error secret.
6.2.5 What Does Differential Privacy Not Protect?
The following example illustrates the types of information disclosures that differential privacy does not aim to address.
It may seem that the publication of the research results enabled a privacy breach by Ellen, as the study’s findings helped her infer new information about John’s elevated cancer risk of which he himself may be unaware. However, Ellen would be able to infer this information about John regardless of his participation in the medical study (i.e., it is a risk that exists in both John’s opt-out scenario and the real-world scenario). Risks of this nature apply to everyone, regardless of whether they shared personal data through the study or not. Differential privacy is a concept specifically designed to allow for studies such as in this example. Therefore, differential privacy does not guarantee that no information about John can be revealed. The use of differential privacy only protects the information that is specific to him, i.e., information about John that cannot be inferred unless an analysis received his personal information as part of the input.
This and similar examples demonstrate that any useful analysis carries a risk of revealing some information about individuals. However, such risks are largely unavoidable. In a world in which data about individuals are collected, analyzed, and published, John cannot expect better privacy protection than is offered by his opt-out scenario, because he has no ability to prevent others from participating in a research study or to prohibit a release of public records. Moreover, the types of information disclosures enabled in John’s opt-out scenario often result in individual and societal benefits. For example, the discovery of a causal relationship between red wine consumption and elevated cancer risk can inform John about possible changes he could make in his habits that would likely have positive effects on his health.
6.3 Aligning Risks, Controls, and Uses: Where Is the Use of Differential Privacy Appropriate?
This section discusses factors to take into account when evaluating whether differential privacy is an appropriate tool to be applied within a specific context, as well as factors in determining whether differential privacy should be deployed alone, in combination with other controls, or as part of a tiered access system. As an overview, Table 6.2 provides some of the key factors that weigh in favor of, or against, an appropriate use of differential privacy. For example, use cases involving statistical analysis of a population or large groups and the possibility of significant and lasting informational harms to individuals weigh heavily in favor of the adoption of differential privacy.
To help guide a systematic analysis of the relevant factors within a specific use case, this discussion follows a framework for selecting privacy controls based on a systematic analysis of harm, informational risk, and intended analytic uses as presented by Altman et al. (2015).
| Use cases where DP is more likely to be appropriate | Use cases where DP is not appropriate | Use cases where DP is challenging |
|---|---|---|
| Informational harm derives from making inferences about individuals or small groups | Informational harm derives from making inferences about large groups | Supporting data linking |
| Intended use is statistical analysis of population or large groups | Intended use is individual inference or individual intervention | Supporting data cleaning |
| Sensitivity of information is high | Intended control is purpose limitation | Estimating complex statistical models efficiently |
| Information and analyses are highly structured | Intended control is computation limitation1 | Datasets are small (e.g., dozens to thousands of observations)2 |
| Datasets are large | Datasets are very small (e.g., less than a few dozen observations) | Differentially private analysis not yet available |
| Types of analyses to be conducted are known in advance | Intended output is high-dimensional synthetic data | |
| Composition effects are important | ||
| Release of (low-dimensional) synthetic data is acceptable or preferred | ||
| 1 A control on computation is designed to ‘’limit the direct operations that can be meaningfully performed on data. Commonly used examples are file-level encryption and interactive analysis systems or model servers. Emerging approaches include secure multiparty computation, functional encryption, homomorphic encryption, and secure public ledgers, eg blockchain technologies.’’ (Altman et al. 2018) | ||
| 2 For a real-world example, see the Opportunity Atlas case study presented in Section 6.4.2 |
6.3.1 Selecting Privacy Controls Based on Harm and Informational Risk: A Framework
Altman et al. (2015) propose a framework for selecting reasonable and appropriate privacy and security measures that are calibrated to the intended uses, threats, harms, and vulnerabilities associated with a specific research activity.111 For applying this framework in practice, Altman et al. (2015) recommend a life-cycle approach to decomposing the factors at each information stage, including the collection, transformation, retention, access and release, and post-access stages. A diagram from Altman et al. (2015) illustrating a partial conceptualization of this framework is reproduced in Figure 6.4. The x-axis represents the sensitivity of the information, or the maximum level of expected harm to an individual in the data resulting from uncontrolled use of the data. The y-axis represents the post-transformation identifiability, or the potential for others to learn about individuals based on the inclusion of their information in the data. Examples range from data sets containing direct or indirect identifiers to data shared using expertly applied rigorous disclosure limitation techniques backed by a formal mathematical proof of privacy (e.g., user-level differential privacy with a low value of \(\varepsilon\)).
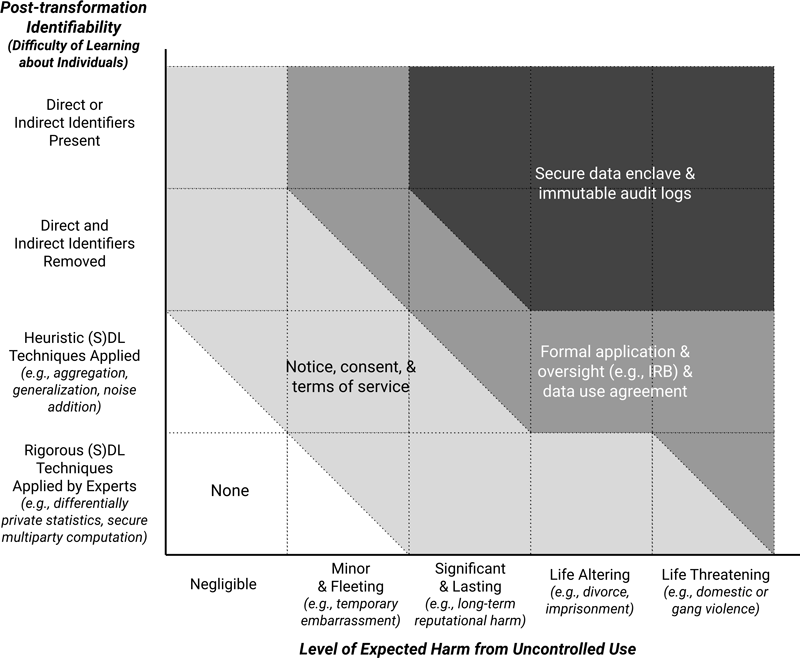
Figure 6.4: Calibrating privacy and security controls
These factors—the level of expected harm from uncontrolled use of the data and the post-transformation identifiability of the data—suggest minimum privacy and security controls that are appropriate in a given case, as shown by the shaded regions in Figure 6.4. The subsets of controls within each region illustrate some possible combinations of controls from the more comprehensive set of procedural, economic, educational, legal, and technical controls (some of which are covered in other chapters of this Handbook). For data associated with only negligible or minor and fleeting harms, the use of differential privacy without any additional controls may be appropriate, but for more significant and lasting or even life altering harms, notice and consent mechanisms as well as terms of service may also be required. Obtaining consent is particularly important when using data for secondary uses not initially disclosed to the data subjects or when the selected value of \(\varepsilon\) is large. For data associated with potentially life-threatening harms, a formal application and oversight process, such as an institutional review board or restricted data access committee, together with a data use agreement may be necessary. As Figure 6.4 illustrates, in many cases, the use of differential privacy allows data analysis projects to be carried out safely with fewer additional privacy and security controls than would be required with other approaches.
Altman et al. (2015) note that the design of a real-world data management plan should consider a wide range of available interventions and incorporate controls at each stage of the lifecycle, including the post-access stage, and not be limited to the choices of controls illustrated in Figure 6.4. “[A]lthough the data transformation and release stages typically attract the most attention, threats and vulnerabilities arising from other lifecycle stages should not be ignored. For example, privacy risks may be present at the collection stage if the data collection process could be observed by an adversary; data retained in long-term storage are vulnerable to unintended breaches; and, increasingly in a big data world, external, independent publication of auxiliary information may create new or unanticipated privacy risks long into the post-access stage” (Altman et al. 2015). Further, one should note that some of the regions in Figure 6.4 are divided by a diagonal line; these areas correspond to situations in which an actor could decide between different choices based on factors related to the intended uses of the data or existing institutional or contractual requirements. It is also important to observe that the recommendations reflected in this diagram may differ from current practice. For example, Altman et al. (2015) argue that data that have been de-identified using simple redaction or other heuristic techniques should in many cases be protected using additional controls.
6.3.2 Considerations When Deciding Whether to Use Differential Privacy
As summarized in Section 6.3.1, differential privacy fits into a broader framework of privacy and security controls that should be applied across the information life cycle to appropriately mitigate risks of informational harm. Within a coherent set of information controls, differential privacy’s primary role is as a formal criterion for disclosure control that ensures limitations on types of inferences that can be made about individuals and small groups based on the outputs of computations. In other words, implementations of differential privacy (especially in the curator model as discussed and contrasted with other models for differential privacy in Appendix A) modify summary information before it is published in order to prevent others from learning any information that is unique and specific to any individual who was part of the group being summarized.
In the context of designing a secure and private information system, differential privacy is used as part of a collection of controls aimed at mitigating informational harm while enabling some types of information uses. Differential privacy is usually neither sufficient protection on its own nor uniquely necessary—and in some cases differential privacy may simply not be appropriate for the intended use.
Three considerations are critical in deciding whether to use differential privacy: (1) how are recipients of protected information intending to use it, and how well do differentially private analyses support these intended uses; (2) what is the nature and degree of informational risk to be mitigated, and are there serious harms that could arise from learning about individuals; and (3) what complementary and alternative controls are available for protecting the data? Each of these questions is discussed in turn below.
How Well Does Differential Privacy Fit the Intended Uses of the Data?
Evaluating the intended uses of the data involves answering a series of sub-questions, including (a) what level of inference is intended; (b) what types of questions, queries, or models must be supported; and (c) how much accuracy is needed?
What Level of Inference is Intended?
Differential privacy is a standard that was designed to support statistical analysis of populations or large groups yet prevent inferences about (and thus interventions targeted to) individuals and very small groups. Consider, for example, the collection, analysis, and sharing of public health information related to the COVID-19 pandemic. Differentially private analyses can be applied in tasks such as estimating the extent to which large communities adhere to social distancing, measuring the efficacy of infection rate reduction measures like social distancing and masks, identifying large disease clusters, and selecting and fitting statistical models of disease transmission.112 If performed with differential privacy these analyses would yield valuable and meaningful statistics while providing strong protection for the privacy of individual medical results, locations, social encounters, etc. If analysis at the individual level is desired (e.g., to identify specific individuals for testing or quarantine) disclosure control methods other than differential privacy should be used. Researchers who intend to prevent certain types of learning about large groups, such as information that could be used to discriminate on the basis of protected group status, should be aware of limitations; while differential privacy protects information that is specific to groups consisting of a small number of individuals, the use of differential privacy alone does not provide protection against group-level inference for larger groups.
What Types of Questions, Queries, or Models Must be Supported?
In theory, with the exception of learning about individuals or small groups, differential privacy could be used to compute any form of answer for any purpose, as it is a constraint on inference, not on purpose or computation (Altman et al. 2018). And in practice, as outlined in Section 6.1.5, a large number of analyses can be performed with differential privacy guarantees.
However, there are some limitations on the current understanding of how to perform certain classes of tasks privately (e.g., the use of differential privacy in analyzing records of textual data is currently limited); how to measure the accuracy or utility of protected results; and how to optimize the privacy versus utility trade-off. Even where algorithms to perform specific calculations are known, robust software that implements these methods may not yet be available. Generally, differentially private tools limit both the number and form of analyses that are possible. Most differentially private tools that provide interactive access to data by design support a limited range of model specifications or statistical operators. For example, a particular tool may allow one to pose queries that can be expressed in terms of counts on definable subsets of the data set (which allows for contingency tables and hence fitting logistic regression models) but not to run any arbitrary statistical model. Similarly, an analyst can apply any model to a non-interactive, synthetically generated data set, but only a limited range of models will return accurate or useful results. Further, it is generally more difficult to apply differential privacy if the methods used by analysts are qualitative, unstructured, or do not lend themselves to rigorous mathematical definitions. Certain queries, such as estimating the number of individuals with specific attributes, are quite straightforward. However, in-depth data cleaning is difficult to define in a sufficiently formal way to apply differential privacy protections to the process.
Appendix C lists currently available software tools for differentially private computation. In general, these tools support a wide range of summary tabulations and summary statistics, the generation of synthetic data sets for some forms of multivariate analysis, and selected applications such as geospatial or location-based analysis. If the intended analyses fall outside of the capabilities of existing tools, one should anticipate that considerably more effort will be required to deploy an effective system in order to support such analyses. This is the case even if the core algorithms for those calculations are already known. Those following this approach should engage experts in differential privacy as part of the design and deployment process.
What is the Required Level of Accuracy?
Differential privacy provides a quantifiable trade-off between privacy and utility (or accuracy). The amount of noise that differential privacy needs to introduce for a single count query is on the order of \(1/\varepsilon\) in which \(\varepsilon\) is the privacy-loss parameter. At minimum, the data set being analyzed must have at least \(1/\varepsilon\) observations to obtain meaningful results. For most analyses, however, the size of the data set must be much larger than \(1/\varepsilon\) to obtain useful results, and how much larger will depend on a number of factors including how many statistics are being calculated, the complexity of the statistical model, the dimensionality of the data, and the particular differentially private algorithm being used. Thus, it is difficult to provide a rule of thumb. In practice, one can run experiments on non-sensitive synthetic or public data as a way to evaluate the accuracy of a tool or algorithm for a given application ahead of time. (Using experiments on the sensitive data to select an algorithm or set its parameters may leak information that violates differential privacy.)
When operating within the framework of existing tools, one should plan to test that outputs remain useful for the intended purposes. There are many different measures of utility and, even if an algorithm does a good job at trading off between utility and privacy, the utility loss for a particular use case may be quite different than the average loss.
6.3.2.1 What Is the Nature and Degree of Informational Risk to be Mitigated?
Another factor to consider when deciding whether to adopt differential privacy is the nature and degree of informational risk to be mitigated. Figure 6.4 illustrates an approach to conceptualizing whether differential privacy is a suitable control to use given different levels of harm associated with uncontrolled use of a particular data set. Some of the relevant questions to consider involve the sensitivity of the information and the potential for risks to accumulate with multiple releases of information about the same individuals or groups of individuals.
How Sensitive are the Data?
When evaluating informational risk, consider the sensitivity of the information or its potential to cause harm to individuals, groups of individuals, or society at large. Generally, information should be treated as sensitive when it reveals information specific to an individual (even partially or probabilistically and possibly in combination with other information) and such inference is likely to cause significant harm to an individual, group, or society.113 Informational harms “may occur directly as the result of a reaction of a data subject or third parties to the information, or indirectly as a result of inferences made from information” (Altman et al. 2015). Applicable laws114 and institutional policies115 may provide some guidance regarding sensitivity, but data may be sensitive and have the potential to cause harm, even if the data do not include categories of information traditionally considered sensitive (Altman et al. 2015). Other key factors increasing informational risk include the number of independent attributes associated with each subject in the data, the scope of intended analytic uses, the number of individuals included in the data, and the size and diversity of the population observed (Altman et al. 2018). Risks can also grow due to characteristics related to time, such as an increase in the amount of time between collection and analysis, in the period of time over which data are collected, and in the frequency of collection (Altman et al. 2018).
Does Composition of Multiple Releases Pose a Significant Threat?
Privacy risk inevitably grows as more computations are released. Differentially private protection mechanisms have the advantage that risk composes predictably and slowly across multiple releases. In contrast, when information is released through other mechanisms, multiple releases could result in sudden and catastrophic loss of privacy.
Absent formal protection mechanisms, it is not possible to definitively assess composition risks ex ante. As general guidance, composition effects are of greatest ex ante concern under the following conditions: (a) data are collected from the same individuals by uncoordinated data controllers, (b) releases are updated frequently, (c) many releases are performed over time, (d) releases are high-dimensional, or (e) prior releases cannot be reliably recalled.116
Alternatively, if the data controller is aware of all potential auxiliary information, it could attempt to assess the cumulative privacy risk post-computation but prior to release. Or, if harm to individuals is readily detected, the data controller could purchase insurance to compensate such harm ex post. These caveats notwithstanding, in the modern information environment, composition risks are generally substantial and ex post formal protections are typically infeasible.
6.3.2.2 What Complementary and Alternative Controls are Available for Protecting the Data?
As illustrated in Figure 6.4, various controls can be complementary to differential privacy. Some examples include contractual approaches for enforcing purpose restrictions, vetting and oversight of analysts for the purpose of privacy budget allocation, and encryption and other information security restrictions on private databases, especially if now exposed to a different set of users through a publicly available differentially private interactive query mechanism. Other tools may be used as an alternative for purposes that differential privacy does not support, such as the role that access via a secure data enclave can play as part of a tiered access system.
Further, a single mode of access will generally not be appropriate for the needs of all users. Different communities of users seek answers to different questions and may have different quality and accuracy requirements even when addressing the same question. It is therefore essential to understand end user usages of inferences and their implied utility and quality criteria (as discussed in Appendix A). An analyst should take these factors into account in particular when allocating the privacy budget across analyses and when selecting the specific interactive and static publication mechanisms to be included.
Tiered access will generally be necessary to accommodate a wide range of desired uses of the data. For a given set of data, access may be made available to different categories of users through different modes of release. Figure 6.4 demonstrates how controls can be selected at each tier. For example, data associated with potential harms that are only minor and fleeting could be released to the public after traditional statistical disclosure limitation techniques, such as aggregation and generalization, have transformed the data. Users who seek to obtain the full data set, including direct and indirect identifiers, would be required to submit an application to an institutional review board or other oversight body, and their use would be subject to the terms of a data use agreement. This approach makes it possible to calibrate data releases to the risk profile of a data set as well as specific uses intended by different data users. Figure 6.5 provides an example of such a tiered access model (see also Sweeney, Crosas, and Bar-Sinai 2015; Crosas 2019).
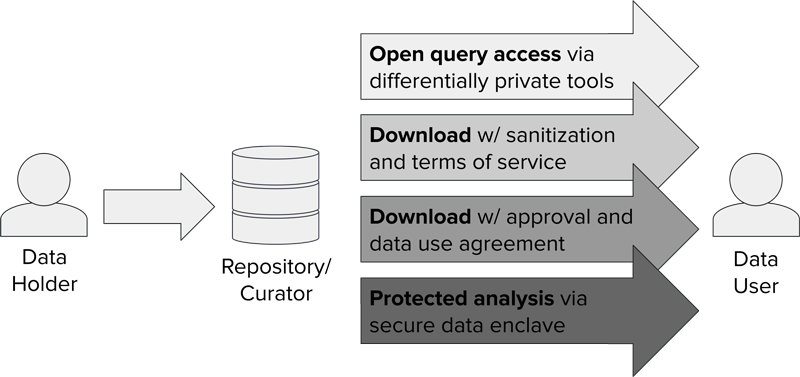
Figure 6.5: An example of a tiered access model
6.3.3 Regulatory and Policy Compliance
Statistical agencies, companies, researchers, and others who collect, process, analyze, store, or share data about individuals must take steps to protect the privacy of the data subjects in accordance with various laws, institutional policies, contracts, ethical codes, and best practices. In some settings, tools that satisfy differential privacy can be used to analyze and share data while both complying with legal obligations and providing strong mathematical guarantees of privacy protection for the individuals in the data (Nissim et al. 2018). Indeed, differentially private tools provide privacy protection that is more robust than that provided by techniques commonly used to satisfy regulatory requirements for privacy protection.
That said, privacy regulations and related guidance do not directly answer the question of whether the use of differentially private tools is sufficient to satisfy existing regulatory requirements for protecting privacy when sharing statistics based on personal data. This issue is complex because privacy laws are often context dependent, and there are significant gaps between differential privacy and the concepts underlying regulatory approaches to privacy protection. Different regulatory requirements are applicable depending on the jurisdiction, sector, actors, and types of information involved. As a result, data sets held by an organization may be subject to different requirements. In some cases, similar or even identical data sets may be subject to different requirements when held by different organizations. In addition, many legal standards for privacy protection are to a large extent open to interpretation and therefore require a case-specific legal analysis by an attorney.
Other challenges arise as a result of differences between the concepts appearing in privacy regulations and those underlying differential privacy. For instance, many laws focus on the presence of personally identifiable information (PII) or the ability to identify an individual’s personal information in a release of records. Such concepts do not have precise definitions, and their meaning in the context of differential privacy applications are especially unclear. In addition, many privacy regulations emphasize particular requirements for protecting privacy when disclosing individual-level data, such as removing PII, which are arguably difficult to interpret and apply when releasing aggregate statistics. While in some cases it may be clear whether a regulatory standard has been met by the use of differential privacy, in other cases—particularly along the boundaries of a standard—there may be considerable uncertainty.
Regulatory requirements relevant to issues of privacy in computation rely on an understanding of a range of different concepts, such as PII, de-identification, linkage, inference, risk, consent, opt-out, and purpose and access restrictions. The definition of differential privacy can arguably be interpreted to address these concepts while accommodating differences in how they are defined across various legal and institutional contexts (Wood et al. 2018). For instance, when differential privacy is used, it can be understood as ensuring that using an individual’s data will not reveal essentially any PII specific to them.117 Differential privacy arguably addresses record linkage in the following sense. Differentially private statistics provably hide the influence of every individual (even small groups of individuals). Although linkage has not been precisely defined, linkage attacks seem to inherently result in revealing that specific individuals participated in an analysis. Because differential privacy protects against learning whether an individual participated in an analysis, it can therefore be understood to protect against linkage. Furthermore, differential privacy provides a robust guarantee of privacy protection that is independent of the auxiliary information available to an attacker. Indeed, under differential privacy, even an attacker utilizing arbitrary auxiliary information cannot learn much more about an individual in a database than they could if that individual’s information were not in the database at all.
The foregoing interpretations of the differential privacy guarantee can be used to demonstrate that in many cases a differentially private mechanism would prevent the types of disclosures of personal information that privacy regulations have been designed to address. Moreover, differentially private tools often provide privacy protection that is more robust than that provided by techniques commonly used to satisfy regulatory requirements for privacy protection. However, further research is needed to develop methods for proving that differential privacy satisfies legal requirements, and setting the privacy loss parameter \(\varepsilon\) based on such requirements is needed.118 In practice, data providers should consult with legal counsel when considering whether differential privacy tools—potentially in combination with other tools for protecting privacy and security—are appropriate within their specific institutional settings.
6.4 Case Studies
Differential privacy is a relatively new concept, first presented in the theoretical computer science literature in 2006 and now seeing early stages of application in real-world settings. This section provides short case studies on three implementations of differential privacy: the 2020 Decennial Census, the Opportunity Atlas, and the Dataverse Project. This discussion focuses on describing aspects of the context in which these differentially private solutions were developed, as well as the design choices that were made with respect to the relevant contextual factors.
This selection of case studies, though limited by the small number of practical implementations of differential privacy to date, aims to reflect a range of different scenarios. The first case study involves a national statistical agency publishing statistical data products from a census, the second involves a team of researchers developing a web-based visualization tool for exploring sensitive administrative data analyzed as part of a research study, and the third describes the functionalities of a general-purpose differential privacy tool being developed for use by data providers and analysts who do not have expertise in differential privacy. Although none of these examples directly describe sharing data from sub-national agencies, they carry real-world lessons relevant to employing differential privacy in such contexts.
Each of the case studies reflects one point in the space of design factors discussed in Section 6.3 and Appendix A. These factors are summarized in Table 6.3. The remainder of this section expands upon critical features of each case and their implications.
| Case Study | Risks & Sensitivity | Tiered Access Controls | Trust & Publication Models | Budget Allocation | Estimating Uncertainty | Granularity |
|---|---|---|---|---|---|---|
| 2020 Decennial Census |
Sensitivity: Data subject to stringent statutory protections. Trust in confidentiality critical to collecting sensitive information from respondents. Risks: Concerns about composition effects and reconstruction attacks motivated adoption of DP. |
Part of a tiered access system that has historically included custom tabulations service for institutional clients; and Research Data Centers for access by vetted individuals to private data. |
Curator model, based on prior data collection design, with cleaning before DP applied. Focus on non-interactive publication of tables. |
Must allocate budget and optimize accuracy for broad range of current and future analyses. | Adopting DP has made noise addition explicit, whereas data users had previously treated Census tables as if they have no error. | Focused both on individuals and households, as appropriate to data measurement design. |
| The Opportunity Atlas |
Sensitivity: Data subject to stringent statutory protections. Risks: Prior methods of de-identification and redaction judged not to sufficiently mitigate risk. |
Original data sources remain available to vetted users through federal Restricted Data Center mechanism. | Curator model applied to previously collected data, with cleaning and linkage (between Census and IRS data) before DP-like methods applied. | Budget analysis focused on balancing privacy vs. societal utility, leading to choice of a rather large epsilon. | Designed to produce uncertainty estimates (taking privacy noise into account) together with quantities of interest, and estimates also calculated in a DP-like manner. | Focused on individuals. |
| Dataverse Repositories |
Sensitivity: General-purpose system designed to support analyses of data of varying degrees of sensitivity. Risks: Vary by data source. DP provides stronger mechanism to mitigate risk than pre-deposit redaction and deidenfication. |
Part of a tiered access model that also supports access to private data with vetting and restricted license. |
Curator model, based on previously collected and deposited data. Supports both non-interactive releases of summary statistics and interactive queries. |
Provides recommended choices of epsilon based on sensitivity of data. Choice to allow per-analyst budgets requires semi-trusted and accountable analysts. |
Important to expose uncertainty estimates from noise due to privacy, both before and after release. | Determined by data depositor. |
6.4.1 The 2020 Decennial Census
In September 2017, the US Census Bureau announced its decision to deploy differential privacy in the disclosure avoidance mechanism for the 2020 Decennial Census (Garfinkel 2017). This decision was motivated in part by the composition effects revealed by a reconstruction attack on the 2010 Census data release (see Section 6.1.2) and the confidentiality and data publication mandates that bind the US Census Bureau.119
In many ways, the data from the US Decennial Census is an excellent fit for differential privacy. Compared to most survey data, it is low-dimensional (i.e., only asks a few questions of each respondent) and the sample size is very large (minimizing the relative impact of the noise added for differential privacy). These features normally would allow for a straightforward application of standard differentially private algorithms (e.g., those which add independent noise to each cell of different cross-tabulations). However, there are a number of other features of the Decennial Census data products that have created challenges and debate among stakeholders over the transition to differential privacy (Garfinkel, Abowd, and Powazek 2018; Hawes 2020; boyd 2020).
First, these data products have a long history of being used for a vast and diverse range of applications, such as apportioning seats in the US House of Representatives, redistricting, funding allocations, provision of local emergency resources, and social science research. To minimize the impact on data users and the software they use, the Census Bureau has decided to produce differentially private data products that have the same form as the traditional products and consist of tables that are exactly consistent with an underlying synthetic data set (rather than a collection of noisy statistics that would be produced by a standard differentially private algorithm), along with other information that needs to be published exactly (e.g., the state population totals). This required the design of custom differentially private algorithms by experts at the Bureau (Garfinkel, Abowd, and Powazek 2018; J. Abowd et al. 2019).
Second, the sources of error in the Decennial Census data products (in particular, disclosure avoidance) have historically not been made explicit and have been largely ignored by data users. Differential privacy is transparent about its noise addition and thus creates concern among stakeholders for the potential impact on their applications. Reconstruction attacks (Dinur and Nissim 2003) tell us that the data products cannot be simultaneously accurate for all possible uses and maintain privacy, leaving the Bureau with the challenging problems of deciding which users and uses to prioritize for accuracy and then optimizing the algorithm and its privacy-loss budget allocation accordingly. To this end, the Bureau published a Federal Register Notice (Bureau of the Census 2018) to understand what aspects of their data products were most important for data users and also released a series of demonstration products showing the impact of potential versions of their differentially private algorithms on past Decennial Censuses.120
Referring to some of the other design choices discussed in Appendix A, the plans for the 2020 Decennial Census are utilizing a curator model (with the US Census Bureau as the trusted curator) with a noninteractive publication model corresponding with the pre-existing data collection and dissemination design. However, historically, access to data from the Decennial Census has not been limited to the public-use products discussed above but have also been made available through other means, including a custom tabulation service for institutional clients and Federal Statistical Research Data Centers for access by vetted individuals. Thus, the planned use of differential privacy fits within an existing tiered access system. It remains to be seen whether and how interactive differential privacy will play a role in subsequent accesses to data from the 2020 Census. Similar to past Census disclosure avoidance systems, the planned algorithm is to be applied after data cleaning edits are performed (Garfinkel 2017). It will enforce privacy at the granularity of individuals as well as at the granularity of households for publications that are based on household characteristics.
Consider the application of differential privacy to the Decennial Census in contrast with another data product from the US Census Bureau— namely, the Post-Secondary Employment Outcomes (PSEO) data (Foote, Machanavajjhala, and McKinney 2019). This data product includes estimates of the cumulative distribution function of earnings for different subsets of the national student population, based on linking college transcripts with Longitudinal Employer-Household Dynamics (LEHD) data. In contrast with the Decennial Census products, this was a new product first released in 2018, so there was no history of entrenched data use that constrained the form of the data release. As a result, it was possible to employ standard differentially private algorithms (namely, binning the earnings within each subset and adding noise to the counts in each bin). Note that the linking of transcript data with LEHD data is done prior to the application of the differentially private algorithm. The PSEO release used a privacy-loss parameter of \(\varepsilon = 1.5\) (US Census Bureau Center for Economic Studies n.d.).
6.4.2 The Opportunity Atlas
The Opportunity Atlas is a web-based visualization tool for exploring social mobility data. It was published as the result of a collaboration between the US Census Bureau, Harvard University, and Brown University (Chetty et al. 2018). The database contains data relevant to understanding children’s economic outcomes in adulthood for every Census tract in the United States. Researchers and policymakers can use the Opportunity Atlas to understand how individuals’ prosperity or poverty is rooted in the neighborhoods in which they grew up and how interventions can be targeted in certain neighborhoods to help more children rise out of poverty.
The Opportunity Atlas is based on data about over 20 million children and their parents, compiled from multiple statistical and administrative data sources. Census data sources include the 2000 and 2010 Decennial Censuses and the American Community Survey. Administrative data sources included de-identified data from IRS income tax returns and data on students receiving Federal Pell Grants, obtained from the US Department of Education’s National Student Loan Data System.
Raj Chetty and John Friedman, Director and Co-Director of the Opportunity Insights research team, respectively, developed the privacy protection mechanism for the Opportunity Atlas in consultation with the US Census Bureau and the Harvard University Privacy Tools Project (Chetty and Friedman 2019). Consistent with the US Census Bureau’s broader efforts to modernize its approach to disclosure limitation (as discussed in Section 6.4.1) and the legal protections for both Census and IRS data,121 the Opportunity Atlas was produced using a method inspired by differential privacy.
Linkage, analysis, and disclosure avoidance were performed in Census facilities. There was a single set of analyses to perform to generate the Opportunity Atlas, and a privacy budget was not reserved for future analyses. They ran simple linear regressions on the data from the Census Bureau and IRS in order to predict child income rank from parent income rank in each Census tract, broken down by race, gender, and other variables. This created challenges for a differentially private solution, as the sample sizes were small (on the order of tens, hundreds, and thousands), and there was sometimes a very small variance in the explanatory variable. However, despite these challenges, the Opportunity Atlas achieved good results using a differential privacy–inspired method. In terms of accuracy, this approach performed better than some traditional statistical disclosure limitation techniques. Indeed, the researchers found that traditional count suppression would have caused them to miss strong relationships that relied on small counts (e.g., between teenage birth rates for black women and the proportion of single parents in Census tracts) (Chetty and Friedman 2019). The Opportunity Atlas also includes uncertainty estimates (standard errors), which are also calculated in a differential privacy–inspired manner.
Chetty and Friedman suggest selecting the privacy-loss parameter (\(\varepsilon\)) using the framework of Abowd and Schmutte (J. M. Abowd and Schmutte 2019), equating the marginal societal benefit of increased accuracy with the marginal cost due to reduced privacy. Given the small sample sizes of the Opportunity Atlas and the importance of accurate data for policymaking, the Opportunity Atlas used (with approval of the Census Bureau Disclosure Review Board) a value of \(\varepsilon\) that is significantly larger than is typically considered in the differential privacy literature. Specifically, they used \(\varepsilon = 8\) for each of several statistics published for each demographic group within a tract.
The Chetty-Friedman method is a general technique, in that it applies to many different statistical estimators (not just simple linear regression). However, it is not formally differentially private, and its privacy properties rely on the same analysis being carried out on many different cells (e.g., many Census tracts as in the Opportunity Atlas). For the specific case of simple linear regression, subsequent work has developed formally differentially private methods that are competitive with the Chetty-Friedman method, and thus may be applied even to releases that do not have the cell structure of the Opportunity Atlas (Alabi et al. 2020).
6.4.3 Dataverse Repositories
The Harvard University Privacy Tools Project122 and the OpenDP initiative123 have been developing a vision for how differential privacy can be incorporated into research data repositories like Dataverse, ICPSR, and Dryad to help human-subjects researchers safely share and analyze sensitive data (Gaboardi et al. 2016; The OpenDP Team 2020). Although these solutions have not yet been deployed at the time of this Handbook, software to support the projects are under active construction and may be available for use in the near future. Thus, this section outlines how differential privacy might fit into some of the ways that research data repositories are used, employing a lightly edited extract from the OpenDP whitepaper (The OpenDP Team 2020). For concreteness, the text is written as specific to using OpenDP software in Dataverse repositories but can be generalized to other repositories and underlying differential privacy software.
Dataverse (King 2007, 2014; Crosas 2011, 2013), developed at Harvard’s Institute for Quantitative Social Science (IQSS) in 2006, enables researchers to share their data sets with the research community through an easy-to-use, customizable web interface, keeping control of, and gaining credit for, their data while the underlying infrastructure provides robust support for good data archival and management practices. Dataverse has been installed and serves as a research data repository in more than fifty institutions worldwide.
Dataverse repositories (like most general-purpose data repositories) currently have little support for hosting privacy-sensitive data. Data sets with sensitive information about human subjects were supposed to be “de-identified” before deposit. Unfortunately, as discussed in Section 6.1.2, research in data privacy starting with (Sweeney 1997) has demonstrated convincingly that traditional de-identification does not provide effective privacy protection. The current alternative to open data sharing in repositories is that researchers depositing a data set (data depositors) declare their data set restricted: the data set would not be made available for download, and the only way for other researchers to obtain access would be through contacting the data depositor and negotiating terms on an ad hoc basis. This approach is also unsatisfactory, as it can require the continued involvement of the data depositor, the negotiations can often take months, and thus it impedes the ability of the research community to verify, replicate, and extend work done by others.
OpenDP can enable Dataverse to offer additional ways to access sensitive data as illustrated by the following use cases.
1. Enabling variable search and exploration of sensitive data sets deposited in the repository
Dataverse already automatically calculates variable summary statistics (counts, min/max, means, etc.) when a tabular file is deposited. These summary statistics for each variable can be viewed using the Data Explorer tool, even without downloading or accessing the data file. As OpenDP is integrated with Dataverse, a data depositor should be able to generate a differentially private (DP) summary statistics metadata file using an OpenDP user interface. To do this, the data depositor would select “Generate DP Summary Statistics” after the tabular data file is ingested in Dataverse, launching the OpenDP interface. Then they would select the privacy-loss parameter for their data file, and OpenDP would create the differentially private summary statistics file and Dataverse would store the newly created metadata file associated with the sensitive tabular data file. Once the data set is published, an end user would be able to view the summary statistics of the sensitive data file using the Data Explorer tool without ever accessing or downloading the actual data file.
2. Facilitating reproducibility of research with sensitive data sets
At least a third of the data sets deposited in Dataverse are replication data and code associated with a published scholarly paper. With OpenDP, data depositors or owners could create a differentially private release on a sensitive data set, which could be used to computationally reproduce the results of the published paper while protecting the privacy of the original data set. In this case, like in Use Case 1 above, a data depositor would select a privacy-loss parameter through the OpenDP user interface and use OpenDP’s statistical query interface to select and run the statistics of choice to create the appropriate replication release. The differentially private replication release file would be made available in the data set and end users would be able to download it, while the original sensitive data set would be protected and not accessible by end users except through the existing processes as above.
3. Enable statistical analysis of sensitive data sets accessible through the repository
For additional flexibility, the data depositor of a sensitive data set could allow for any researcher (end user) to be able to run any statistic available through the OpenDP interface. In this case, the data depositor would configure the allocation of privacy-loss budgets through the OpenDP interface before releasing the data set. Once the data set is published, an end user would be able to click “explore” for the sensitive data file, and the OpenDP statistical query interface would open. The user would not have access to the original sensitive data file but would be able to run the statistics of their choice—up to the point that the established privacy-loss budget allows.
Referring to some of the other design choices discussed in Appendix A, the vision outlined above fits into the curator model of differential privacy, as researchers depositing data in the repository have typically already been trusted to collect the sensitive data. It is part of a tiered access model meant to augment rather than replace the existing methods of accessing restricted data. Use Cases 1 and 2 involve noninteractive releases, whereas Use Case 3 allows for interactive queries. Many of the other key choices associated with implementing differential privacy are left to the data depositor, who cannot be expected to have expertise in differential privacy. Thus, the software tools must provide a clear user interface to guide the depositor in their decisions. There should be a tutorial on the concepts of privacy loss, privacy–accuracy trade-offs, and budgeting, including recommended choices of privacy-loss parameter \(\varepsilon\) according to different categories of data and sensitivity. The depositor should also be guided in defining the granularity of privacy appropriate for their data and the trade-offs between offering per-analyst budgets for interactive queries versus a global budget for all queries. Domain knowledge will be required of the depositor (and the analyst in Use Case 3) in deciding which statistics to release and which ones to prioritize for accuracy. For the research use cases described above, it will be important that the differentially private analyses offered provide uncertainty estimates whenever possible.
Disclaimer
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of their funders.
Acknowledgements
Work of Kobbi Nissim, Salil Vadhan, and Alexandra Wood was partially supported by the US Census Bureau under cooperative agreement No. CB16ADR0160001. Salil Vadhan was also partially supported by a Simons Investigator Award. The authors thank their coauthors on those papers, as well as Jean-François Couchot and Jean-Marc Gervais for their inquiries that led us to uncover a mistake in the calculation of Table 6.1; Mercè Crosas, Raj Chetty, and John Friedman for their comments on the case studies; Marco Gaboardi and Michael Hay for help with software tools; and Simson Garfinkel, Steven Glazerman, Michel José Reymond, Jayshree Sarathy, Anja Sautmann, Lars Vilhuber, and the members of the Bridging Privacy Definitions Working Group for their review comments on earlier drafts.
Appendix
Appendix A: Key Design Choices
This section identifies the key design choices that critically affect the use of differential privacy. It introduces the trade-offs that should be considered and decisions that must be made when implementing differential privacy. Since many of these choices have broad implications for other information lifecycle activities, such as record management and compliance, these topics are discussed in Appendix B.
While there is no one-size-fits-all solution and it is impossible to summarize all of the literature related to the foundational research and applications in these areas, this overview is intended to help organizations consider a set of trade-offs and decision points critical to designing a differentially private system. These are decisions that should be made explicitly at the planning stage, as failing to do so will almost undoubtedly lead to challenges later.
Trust: Local versus Curator Model, and Alternative Distributed Models
Differentially private computations have been designed for a spectrum of trust environments, and an organization implementing differential privacy must decide which is most appropriate for its particular use cases. On one end of the spectrum, the curator model (also known as the centralized model) of differential privacy assumes the existence of a trusted party. The trusted party collects personal information, produces its outputs by applying differentially private computations, and is trusted to otherwise protect the data from potential adversaries. On the other end of the spectrum, the local model of differential privacy is a fully distributed model which assumes no trust, except of individuals in their own computations (i.e., that individuals’ computing devices are operating properly, that the security of their devices are not compromised, that the software they run are trustworthy, etc.).
The curator model is the most well-studied and well-understood model for differential privacy, and most of the discussion in this chapter is written with the curator model in mind. The downside of the curator model is the assumed trust: data subjects must trust the curator to keep their data stored securely, inaccessible to adversaries including external hackers as well as insiders within the curator’s organization. The curator must also be entrusted to enforce a satisfactory privacy-loss budget for the data and carry out differentially private computations in a correctly implemented and secure manner.
The local model for differential privacy found large-scale adoption by companies like Google (Erlingsson, Pihur, and Korolova 2014), Apple (A. Differential Privacy Team 2017), and Microsoft (Ding, Kulkarni, and Yekhanin 2017) because of the strong privacy protections the model affords. Each of the individual pieces of personal information collected using a local model is infused with statistical noise that is introduced at the endpoints (i.e., on the data subjects’ devices). As a consequence, each subject’s privacy is protected (as long as the subject’s device operates with the correct software and is not otherwise compromised) even if the aggregating party (e.g., the company analyzing the data) and all other subjects’ devices are compromised (e.g., by hacking or by a subpoena). However, the local model comes at a large cost in statistical accuracy. Indeed, in contrast to the curator model, the noise introduced for privacy in the local model is generally larger than the sampling error even as the number \(n\) of observations tends to infinity. This effect makes it applicable mostly for analysis over massive data sets, such as the user bases of the aforementioned large technology companies.
Researchers are investigating alternative distributed models for differential privacy that fall in the middle of this spectrum. These approaches aim to provide privacy protections that are qualitatively stronger than the centralized model (in the sense of relying on weaker trust assumptions than that of the centralized model) with improved accuracy compared to the local model. Three such alternatives are computational multiparty differential privacy (Vadhan 2017, secs. 9–10), the hybrid model (Avent et al. 2017), and the shuffle model (Bittau et al. 2017; Cheu et al. 2019).
Interactive versus Noninteractive Publication Mechanisms
When deploying differential privacy, one must decide whether to employ a noninteractive mechanism, an interactive mechanism, or a hybrid of the two. This discussion introduces each of these approaches, and Appendix B below outlines the advantages and disadvantages of each approach at different stages of the information life cycle.
A noninteractive mechanism can be thought of as a data publication system. The data custodian decides what kinds of statistical releases to make on a sensitive data set, computes them in a differentially private manner, and then publishes the results. Common forms of statistical releases from a noninteractive differentially private mechanism include descriptive statistics about the individual variables in the data set (e.g., approximate means, medians, quantiles, histograms), contingency tables (i.e., cross-tabulations), machine learning models, and synthetic microdata.
The alternative is an interactive mechanism, which allows data analysts to submit queries (e.g., a particular regression they would like to run) and differentially private answers are provided in response. The interactive mechanism ensures not only that each individual query is answered in a differentially private manner but that accumulated privacy loss is within the desired budget.
Interactive mechanisms have the advantage that the releases are tailored to the interests of the individual data analysts, which may not be known by the data custodian in advance. Indeed, with a noninteractive release (e.g., synthetic microdata generated by a statistical model fit to the data), the analyses that can be subsequently carried out are limited to whatever statistical properties are captured by chosen releases (e.g., one may not be able to fit an entirely different statistical model to the data). On the other hand, deciding on all releases in advance (as in a noninteractive mechanism) provides a greater opportunity to optimize the algorithms producing those releases (and to determine how the privacy-loss budget is allocated among them). Moreover, after a noninteractive release, the sensitive data set can be destroyed or stored in a highly secure and inaccessible manner, whereas fielding interactive queries requires keeping the data set somewhat accessible, and thus opens another attack surface.
To obtain some of the benefits of both models, it is possible to employ a hybrid approach, where some of the privacy-loss budget is used for a noninteractive release, and the remainder is reserved to field interactive queries.
Managing the Privacy-Loss Budget and Utility Trade-offs
Many important decisions about sharing data with differential privacy involve how the privacy-loss budget is determined and managed. Even for a single noninteractive release with a precisely defined measure of utility, one must select a point on the privacy–accuracy trade-off curve, which requires balancing societal benefits from releasing more accurate statistics with obligations to maintain the privacy of the data subjects (J. M. Abowd and Schmutte 2019).
This balancing can be difficult because privacy and accuracy are generally measured in incomparable units, and translating them both to a common utility measure (like dollars of benefit or harm) typically requires making many contextual and stylized assumptions (as in the insurance premium examples of Section 6.2.3. Thus, a common alternative approach is to separately consider (a) what is the maximum level of privacy loss that is acceptable and (b) what is the minimum level of accuracy to make the released data fit for use, see if there are differentially private algorithms that achieve both, and then make adjustments from there.
This problem becomes even more challenging if there are many data users who will employ the released statistics in varied ways (and thus have different measures of utility). Optimizing a released model or collection of tables for one set of uses may result in reduced utility for other uses. This is one of the major issues facing the US Census Bureau in developing its disclosure avoidance system for the 2020 Decennial Census (Hawes 2020). (See Section 6.4.1 for more discussion.) In the context of an interactive query system (or a hybrid system), this problem manifests itself as how to partition the overall privacy-loss budget among different data analysts (and possibly an initial noninteractive release).
It is important to note that the need to make choices about which uses to prioritize does not arise because of the use of differential privacy. Rather, the attacks mentioned in Section 6.1.2 indicate that it is impossible to support all statistical uses of data without compromising privacy. Differential privacy merely provides a framework for confronting and managing this trade-off. That said, there are several approaches to make the management of the privacy-loss budget and its trade-off with accuracy less severe:
Create better differentially private algorithms. A number of more sophisticated differentially private algorithms automatically detect relationships among different queries and correlate the noise used to answer the queries so that all of them can be answered using less of the privacy-loss budget than if they were treated independently. In theory, these methods can sometimes allow for an exponential increase in the number of queries answered (for a given accuracy and overall privacy-loss budget).
Ensure secrecy of the sample. If the individuals in a data set consist of a simple random sample from a larger population (and potential privacy adversaries do not have information about whether a target subject is part of the sample), then one can take advantage of a privacy amplification phenomenon, whereby the randomness of sampling process reduces the privacy-loss to each data subject. (See Balle, Barthe, and Gaboardi (2018) for a state-of-the-art analysis of simple random samples and (Bun et al. 2020) for an initial investigation of more complex sampling designs.)
Establish per-analyst budgets. If different analysts can be trusted to not collude and share the results of their queries with each other (in particular, an adversary cannot pose as multiple non-colluding analysts), then it may be reasonable to give them overlapping portions of the privacy-loss budget. Note that this also requires limiting the extent to which analysts can publish based on the results of their queries. If the analysts are untrusted or unconstrained, then they must share the overall privacy-loss budget.
When managing the privacy-loss budget, one should also consider future needs for privacy and utility. If the data will need to be analyzed in unanticipated ways (or in combination with new data that are not yet available) in the future, then some of the privacy-loss budget should be reserved for those uses. In some cases, privacy considerations may diminish in the future, allowing the privacy-loss budget to be increased over time. For example, the US Census Bureau releases all data collected from the Decennial Census after 72 years (Bureau, n.d.).
Dwork, Kohli, and Mulligan (2019) survey a number of practitioners of differential privacy about how the practitioners set and managed their privacy-loss budgets, and the researchers propose the creation of an “Epsilon Registry” to build a communal body of knowledge about these choices.
Specifying the Granularity and Measure of Privacy
An organization designing a differentially private implementation should also consider the granularity of privacy (i.e., the unit of information to be protected). The concept of differential privacy can be applied to any form of data set as long as one can specify the granularity of privacy.124 For example, if a data set is a social network graph and one wishes to protect individual members of the network, then the researcher could take the granularity of privacy to be any node and all incident edges, as this represents a single individual’s contribution to the graph. In an individual’s opt-out scenario, one would consider removing that individual and all of their relationships from the social network. Similarly, in a data set of online purchases, the granularity of privacy could be all transactions that have been carried out by a single user. Additionally, there is no fundamental reason that the granularity of privacy must correspond to individual human beings. For instance, in some contexts, one might wish to protect the privacy of individual households or individual corporations.
Counterintuitively, to correctly apply differential privacy, the underlying data set must sometimes retain information that distinguishes one individual from another. Indeed, if one removed user IDs from the aforementioned example of online purchases, then it may be impossible to ensure a desired level of privacy protection for each individual user; one could protect individual transactions but that would not necessarily yield effective protections for a user involved in many transactions.125 Similarly, if the data are already aggregated (for example, a collection of counts specifying how many times each item was purchased), one may not be able to characterize a single individual’s contribution and properly apply differential privacy.
Another choice is how the privacy loss is measured. While the text has presented the basic concept of pure differential privacy, which measures privacy loss by the single parameter \(\varepsilon\), there are now several other measures of privacy loss that involve two or more parameters (e.g., approximate differential privacy, concentrated differential privacy, and Rényi differential privacy). These yield relaxations of differential privacy that are motivated by obtaining better privacy–utility trade-offs and/or by having better composition properties. For example,, approximate differential privacy is parameterized by two parameters \(\varepsilon\) and \(\delta\)and can be informally interpreted as “\(\varepsilon\)-differential privacy except with probability \(\delta\),” and thus affords similar protections as pure \(\varepsilon\)-differential privacy if \(\delta\) is taken to be extremely small (e.g., \(\delta \leq 1/10^{9}\)). Other forms of differential privacy are somewhat more complex to interpret so may require expert guidance in setting the privacy-loss parameters.
Estimating and Communicating Statistical Uncertainty
Like all statistical disclosure limitation methods, the perturbations introduced by differential privacy increase the risk that data analysts will draw incorrect conclusions from the released statistics. There are several ways to prevent or mitigate this problem, depending on the statistical sophistication of the data users, the nature of the published statistics, and the techniques supported by the software being used. One possibility is to use differentially private algorithms that quantify uncertainty (e.g., through confidence intervals, standard errors, or \(p\)-values) along with their point estimates. This is generally easy for simple empirical quantities (e.g., estimating the number of people in the data set with some condition), but it is more challenging (and an active area of research) when estimating population quantities (in which the uncertainty due to privacy needs to be combined with the uncertainty due to the sampling of the data set from the population) or when the estimator itself is more complex (e.g., fitting a regression model).
When generating differentially private synthetic data that will be used for many different purposes, it is also difficult to provide uncertainty estimates for unanticipated uses. For these more challenging scenarios, Monte Carlo simulations on synthetic or public data can be used to gauge accuracy and uncertainty. Publishing the code for the differentially private algorithms allows any data user to carry out such experiments on their own. Publishing the exact algorithms may also allow data users who are sophisticated statisticians to directly account for the differentially private algorithms when performing inference using the published results.
The use cases described in Section 6.4 illustrate some of the above approaches: the Opportunity Atlas (Section 6.4.2) releases explicit estimates of uncertainty and the 2020 Decennial Census (Section 6.4.1) releases code and demonstration products to help users evaluate accuracy and uncertainty for the future releases.
Appendix B: Implications for Compliance and Life Cycle Data Management
The design choices involving the use of differentially private analyses, discussed in Appendix A, potentially have broad implications for data curation, stewardship, management, and preservation, as well as regulatory compliance. For example, choosing a local model design (as described in Appendix A) fundamentally affects not only how data are collected. It also fundamentally limits the way the design can be linked with other data, the extent to which the information collected can be reused, and, potentially, the compliance requirements with respect to data storage and retention. This section discusses the implications of the key design across the information life cycle.
This chapter uses the information life cycle model described in Altman et al. (2015)—which is adapted for the uses of privacy engineering from the more generic model developed by Higgins (2008) to systematically trace design,—and the implications of the design choices described above for data collection, curation, preservation, reuse, and compliance.
The stages of the information life cycle model are defined generally as follows:
Collection is defined broadly to include acceptance, ingestion, acquisition, or receipt of data.
Transformation of data encompasses a range of alterations, which may be structural or semantic and lossy or lossless. Although transformations such as data cleaning typically occur following collection, a variety of transformations may be combined with, or interleaved with, subsequent stages.
Retention broadly includes any form of non-transient storage by the data controller or a party acting under the controller’s direction. Retention requirements are generally coupled with processes for data disposal or destruction for use when retention is completed.
Access describes any transformation, subset, or derivative of the data by a party not acting under the direction of the data controller.
Post-Access refers broadly to operations occurring after information has been released from, or exited, the formal organizational bounds of the information system.
The remainder of this section discusses specific implications of using differential privacy at each stage.
Collection
At the collection stage, measurement design,126 consent, and compliance are particularly affected by the choice of differential privacy trust model, privacy granularity, and computing of the utility considerations.
Measurement Design
With respect to measurement, the unit of identification for the chosen granularity of privacy must be collected. For example, if one aims to protect the privacy of individuals, it must be possible to identify when the same individual is being observed multiple times during collection, as applying protection to individual events or observations will not protect individual privacy.
While any approach to disclosure control requires anticipating how data will be used, differential privacy’s rigorous approach to tracking privacy loss leaves less room to offer a range of analyses “just in case” they are useful. Thus, one should model in advance what analyses will be offered and how differing levels of precision and accuracy affect utility; then choose sample sizes that will provide both sufficient utility and privacy.
Finally, if the local trust model is used, elements of the research design must be altered in order to achieve useful results: the measurement design may require alteration, only a subset of possible statistics are estimable under that model, computing statistics from measurements made under the local model are more complex, and larger samples will be needed to achieve a target level of accuracy.
Consent
Use of differential privacy may affect approaches toward consent. Where the choice of the granularity of privacy is defined as the observed individual, it may be appropriate in some circumstances to allow for access to the data via differential privacy without consent. Further, it may be appropriate in some circumstances to use the local model in order to collect effectively anonymous or de-identified data, which may consequently lead to less reliance on consent mechanisms.127 The ethical rationale for consent depends both on the learning risks and the potential harm from a data release, as illustrated above in Figure 6.4. For instance, the more sensitive the data the stronger the rationale is for consent as a complementary control.
There is wide variation in regulatory requirements regarding the role of consent; definitions of anonymous, de-identified, or nonpersonal information; and the interactions among these concepts. Differential privacy can arguably substitute for consent when all of the following conditions apply: (1) regulations do not require consent for use of anonymous or de-identified information, (2) broad use of anonymous data without consent is ethically acceptable, and (3) the choices of trust model and granularity of privacy are appropriate, and the privacy-loss budget is sufficiently small (e.g., sufficient for anonymization, see below). Alternatively, additional consent may be required when information is especially sensitive, or when regulations do not exempt anonymous information. Further consent may be desirable when it serves to promote awareness and control of risks that are not derived from inferences on controlled data releases (e.g., risks of data collection, security breaches), or when there are ethical or legal reasons to promote awareness and control of risks to other than the unit of granularity (e.g., society, large groups) and provide control over the purposes for which (possibly anonymous) data may be used. Consent mechanisms for the use of differential privacy should describe that formal privacy protections are provided, specify the uses of the information, and provide access to details regarding the privacy-loss budget and the granularity of privacy adopted.
As discussed, more sensitive data demand greater protection. Moreover, when sensitive attributes are collected, consent is particularly important for both ethical and legal reasons. Because differential privacy supports allocation of the privacy budget across analyses and not measurements or characteristics, the privacy budget for the entire set of analyses should be calibrated to the most sensitive measurements included in the data. Further, selecting a local trust model can reduce the downstream risks associated with collecting sensitive estimates. However, it is rarely appropriate to rely on differential privacy as the sole protection for sensitive data—and never appropriate when the selected privacy-loss budget is large.
Compliance: Identifiability and Anonymization
When privacy regulations establish threshold concepts of anonymization or minimal risk, differential privacy may be used to help satisfy such requirements, as described above in Section 6.3.3. These depend critically on using appropriate choices of privacy-loss budget and granularity of privacy. This text argues that differential privacy applied at the granularity of the individual with epsilon set to a small number, such as 0.1 or less, should be considered sufficient protection.128 A privacy-loss budget of 0.1 may, however, be more restrictive than what is considered sufficient under a specific interpretation of a privacy regulation, or what is deemed appropriate when balanced with utility considerations; making a determination within a particular regulatory domain requires a context-specific analysis.129
Compliance: Information Security
When deploying differential privacy using the curator model, the curated sensitive data must be protected from unauthorized access. Further, when public facing interactive front-end access mechanisms are deployed to provide DP-protected queries, the back end of that public service typically requires dynamic access to the sensitive database. In contrast, the local model of trust can be used to provide effective anonymization on collection, which can reduce information security requirements downstream. Under many legal regimes, anonymized data are not subject to technical restrictions (such as encryption) on storage and transmission or to related restrictions (such as security audits or breach reporting).130
Transformation
The choice of differential privacy trust model has implications for the ability to perform later transformations, data cleaning, and linking.
Data cleaning
A data cleaning procedure that applies a fixed transformation to each individual observation can be performed both in the curator and the local models of differential privacy without affecting the overall privacy-loss budget. Here, a fixed transformation means a transformation that is chosen without consulting the sensitive data. For example, this might include replacing missing or invalid values with a default value or a random value chosen from a fixed distribution that does not depend on the sensitive data.
The situation becomes more complicated when the transformation requires a global computation on the data set as a whole. Such cleaning transformations are virtually irrelevant for the local model, as they are complex (or even impossible) to deploy in such a distributed manner. The curator model, however, makes it possible to apply such data cleaning procedures, but privacy-loss from data cleaning operations should ideally be subtracted from the overall privacy-loss budget to maintain the formal differential privacy guarantee. Only a few formally private data cleaning mechanisms are available, such as (Ge et al. 2019; Krishnan et al. 2016). In the current practice, the details and diagnostics from cleaning operations are usually not made available to the public and the effects of cleaning on the privacy budget are often ignored.
Data linkage
Many times, data users wish to analyze not just a single sensitive data set but carry out an analysis on several linked data sets, some of which may be sensitive and some of which may be public data. If there is a single curator who can be trusted with all of the sensitive data sets to be linked, then differential privacy can be applied to this context in a relatively straightforward manner (in principle).
Specifically, one need only to be able to define the granularity of privacy—namely, what is an individual’s contribution to the collection of sensitive data sets. For example, in a collection of relational databases that have a key corresponding to individuals, the granularity of privacy could be defined by all records that involve that individual’s key. There are some differential privacy software tools that can be applied directly to multi-relational databases in this way. Others require that the data set be a single table where the granularity of privacy is one record, and thus a multi-relational database would have to be transformed into such a format before applying differential privacy. An example of this single-curator application of differential privacy on linked data is the Opportunity Atlas based on Census and IRS data described in Section 6.4.2.
On the other hand, if the sensitive data sets are held by different data custodians and cannot be entrusted to any one curator, then carrying out a joint analysis is more challenging. One approach is to issue separate differentially private queries to each data set, but this limits the kinds of analyses that can be performed. Another is to combine differential privacy with secure multiparty computation or trusted execution environments as described in Appendix A.
Retention
At the retention stage, compliance, information security, and costs may be affected by the choice of trust and publication models.
Compliance
The curator model presents the greatest potential compliance obligation. Because the data are held by the controller in identifiable form, they may be subject to both reporting and correction requirements.
The use of the local model reduces the risk from disclosure of personal data retained by a data controller, hence reducing information security risks and requirements. With respect to compliance, the local model may render data anonymous, as discussed in more detail above in Appendix B. This may reduce or even eliminate compliance requirements that apply to the storage and destruction of personal data. However, in some cases, the use of the local model is arguably in tension with requirements to support the right to correct one’s personal data retained by a data controller.
Information Security and Costs
Because the curator model involves retaining sensitive identifiable data, information security risks are higher, and the costs of compensating information controls increase. Combining the curator model and interactive data publication models creates additional risks and costs because sensitive data must be available to the public interactive query mechanism.131
Access
At the access stage, information security, utility, costs, and compliance are all affected by the full range of choices made when deploying differential privacy, with choices related to trust, publication, and utility having the most impact. Further, because differential privacy always yields results that are statistical estimates and not exact counts, communication of uncertainty is a key part of designing access.
Information Security
Security is affected by the trust model and publication choices, similar to what was described at the retention stage. If the curator model is used, then interactive data publication expands the vulnerability surface, as private data must be continuously available to enable a public-facing interactive service. Further interactive data publication increases the risk of a persistent denial-of-service attack against the privacy budget. For example, unless separate budgets are allocated per analyst, one user may exhaust all future queries.
Compliance
Compliance with privacy regulations and policies is affected by the trust model and can be complemented with other controls, similar to what was described in Appendix B. All of these factors affect the cost profile, but the interactive model is particularly significant because computations must be done centrally, and the system has to be available and accessible for the useful lifetime of the data. Further, as discussed in Appendix B, interactive data publication increases the cost of access because all computations and access are mediated by the data controller, compared to noninteractive releases in which each researcher performs computations on a local copy of a static data publication without mediation by the data controller.
Utility
The choices of trust model and privacy budget have substantial implications for formal measures of utility. Further, the choice of specific data analyses to be released, and differentially private algorithms deployed, will also substantially affect utility.
Communicating Uncertainty
Analyses produced using differential privacy are always uncertain but should be truthful.132 Differential privacy is designed for statistical estimates and is capable of producing these truthfully.
Often, the contribution of the differential privacy protection to the total error of estimation will not dominate the total error of estimation. Ideally, one should both manage and communicate the total error (including sampling and non-sampling errors) (Biemer 2010) associated with all released information.
Further, when differential privacy is used for static publication of (typically synthetic) microdata, information should be provided about the restrictions that the design imposes on truthful statements. For example, a differentially private synthetic microdata release may be designed to preserve bivariate relationships but not trivariate ones. Therefore, in this case, the release would be incapable of producing truthful statements about the latter, and this limitation should be communicated to the user.
Post-Access
At the post-access stage, preservation, replication and verification, utility assessment, and compliance with reporting and disposal requirements are affected by the trust model and publication model.
Preservation and records management
Preservation can be thought of as communication with the future. In the context of records management (i.e., the maintenance of authoritative records as evidence for a designated period consistent with policy), preservation is the transmission of authentic, reliable information contained in data to future parties. Replication of content across institutional boundaries and independent auditing are necessary conditions for long-term preservation. The implementation of differential privacy may have the effect of shifting the form of official or authoritative and public outputs from transformed databases to query results. This happens when a data provider makes the decision to adopt an interactive mechanism for data access when it had previously employed a non-interactive mechanism. This shifts the target of preservation and record management and the methods that can be applied.
When interactive approaches are used to repeatedly derive statistical results from private data (using the curator model), the data provider may need to both preserve and manage outputs from the interactive mechanism and replicate the underlying private data (often with additional protections) for future analysis and verification. Further, while it is straightforward to replicate and preserve static data publications, durable access through an interactive service requires continuous maintenance and institutional commitment. The multi-institutional replication necessary for preservation of such privately-held data (Rosenthal et al. 2005; Reich and Rosenthal 2009) may be difficult to achieve because each institution must protect the data, though replications of encrypted versions may mitigate both individual and institutional risks.
In contrast, if only static data publication is used to support authoritative decisions, then preservation of those outputs using standard processes is sufficient. Similarly, if the local model is used for data collection, the sensitivity of the database may be reduced sufficiently so that existing processes for preservation and auditing of content can be used.
Replication, Verification, and Reuse
Generally, reproducibility or replicability addresses what parts of published outputs and inferences can be independently produced at a later time for verification, robustness analysis, and re-specification.133 These goals differ from those of reuse, which is use of the data by other parties for separate purposes or inferences. The trade-offs for reproducibility are similar to those for preservation.
Design choices such as the choice of interactive versus static data collection (e.g., local versus curator model) and publishing (e.g., model server versus synthetic data and other static outputs) have strong implications for reproducibility. Local model data are de-risked so they can be shared for replication. With the local model, data can be redistributed for exact independent analysis (replication), but re-specification will be constrained, and data collected in this form are unlikely to have much utility for reuse. With the curator model and static publication of synthetic data, more replication and reuse are possible, though they are constrained by the structural relationships modeled in the synthetic data generation process. Reuse of results from static data publication is more straightforward than replication, verification, or robustness analysis of a computation gated by an interactive server. However, as long as the underlying private data are preserved, verification is possible—if one trusts the data controller to execute a separate analysis properly and if enough of the privacy budget remains to release the outputs. Differential privacy also has the advantage that the method and parameters are transparent and can be released without endangering privacy.
Interactive results are not designed for reuse. Static data can be reused for arbitrary analysis but may be useful only for the types of analyses they were planned to support. Similarly, data collected via a local model of differential privacy may not be useful to reuse for other purposes. In an interactive publication model, private data remains available to reuse in a more exclusive tier.
Utility
Achieving an optimal privacy–utility trade-off requires monitoring both use and utility. This is particularly important with interactive data release mechanisms (which are typically used for differential privacy) for which it is possible to evaluate the actual utility loss for each query. Moreover, since each query permanently decreases the remaining privacy budget, it is important to recognize in a timely manner patterns of use that are not, in practice, providing good utility for the amount of privacy loss.
Compliance
The choice of differential privacy implementation may also affect downstream compliance requirements. This is because, under many regulatory regimes, only data that are identified carry requirements for disposal, notification, and/or correction. Under these regimes, data collected may not be subject to further compliance requirements.134
In contrast, if data are collected under the curator model, disposal of instances (or backup copies made for administrative reasons, copies on systems being retired, etc.) must be managed (e.g., by encrypting the data at rest and using secure erasure methods). In addition, as discussed in Appendix B, use of the curator model implies that sensitive information is retained by the controller in identifiable form. Consequently, this may subject the controller to requirements for breach reporting, individual access, and individual correction and deletion.
Summary of Life Cycle Implications of Design Choices
Table 6.4 provides a summary of the implications of design choices at each life cycle stage.
| Key Dimensions | Collection | Transformation | Retention | Access | Post-Access | |
|---|---|---|---|---|---|---|
| Trust Model |
|
|
|
|
|
|
| Data Publi- cation Model |
|
|
|
|
|
|
| Privacy Granu- larity |
|
|
|
|||
| Privacy Budget Alloca- tion |
|
|
|
|
|
|
| Utility Con- sidera- tions |
|
|
|
|
|
Appendix C: Additional Resources
This section provides a brief survey of software tools and other resources for practitioners considering potential steps towards implementing differential privacy within their organizations.
Available Tools for Differentially Private Analysis
The landscape of software tools for differential privacy is rapidly evolving. A few years before this chapter was written, almost all of the publicly available tools were research prototypes, meant as proof-of-concepts but not sufficiently polished or vetted to be used in production. In particular, some had security vulnerabilities that an attacker could exploit to negate the protections of differential privacy (Haeberlen, Pierce, and Narayan 2011; Mironov 2012). However, in recent years there have been serious efforts from industry and academia to produce usable and deployable differential privacy tools. Below, some of these efforts are listed as a starting point for organizations seeking practical tools for differentially private analysis.
It is important to note several caveats. First, inclusion of a tool or project in this list is not an endorsement, and the ordering is merely alphabetical within each category. Second, the tools are in varying stages of development. Some may be near-production code, while others may still have security vulnerabilities or are only safe to use for noninteractive releases by a trusted data controller (so that an adversary cannot exploit vulnerabilities by interacting with the system). Third, few, if any, of the tools are ready to use off-the-shelf; some expertise in software and data management will be needed to deploy them. Fourth, as when deploying any software, one should (a) check if it is still being actively maintained, (b) ask what kind of vetting and security review the code has undergone, and (c) perform thorough experiments to evaluate how the utility and functionality fit one’s needs. Finally, this list will, undoubtedly, soon fall out of date. Caveats notwithstanding, the authors believe this list will provide a good starting point when searching for an appropriate solution.
General-Purpose Software Tools and Repositories
The following are some software tools and projects for general-purpose differentially private analysis that are both actively developed and publicly available:
Diffprivlib (Holohan et al. 2019):135 Developed by IBM, “Diffprivlib is a general-purpose library for experimenting with, [and] investigating and developing applications in, differential privacy.”136 In particular, it allows one to “explore the impact of differential privacy on machine learning accuracy using classification and clustering models.”137 It is designed to be used from Python.
Google Differential Privacy Library (Wilson et al. 2020):138 Google’s differentially privacy library project “contains a set of libraries of … differentially private algorithms, which can be used to produce aggregate statistics over numeric data sets containing private or sensitive information. The functionality is currently available in C++, Go and Java.”139 This project also contains “an end-to-end differential privacy solution built on Apache Beam and [the] Go differential privacy library,” as well as other tools.140
NIST Privacy Engineering Collaboration Space:141 The National Institute of Standards and Technology provides “an online venue open to the public where practitioners can discover, share, discuss, and improve upon open source tools, solutions, and processes that support privacy engineering and risk management.”142 In the category of de-identification tools, the space includes a number of repositories for differential privacy software, including the algorithms submitted to NIST’s 2018 Differential Privacy Synthetic Data Challenge.
OpenDP (The OpenDP Team 2020):143 “OpenDP is a community effort to build a trustworthy suite of open-source tools for enabling privacy-protective analysis of sensitive personal data, focused on a library of algorithms for generating differentially private statistical releases. The target use cases for OpenDP are to enable government, industry, and academic institutions to safely and confidently share sensitive data to support scientifically oriented research and exploration in the public interest” (The OpenDP Team 2020).
OpenMined:144 “OpenMined is an open-source community whose goal is to make the world more privacy-preserving by lowering the barrier-to-entry to private AI technologies.”145 OpenMined includes several libraries and platforms for differential privacy, including PyDP,146 which is a Python wrapper for Google’s Differential Privacy Library.
Overlook (Thaker et al. 2020):147 This project incorporates differential privacy into Hillview, which is “a cloud-based service for visualizing interactively large datasets.”148
Tools for Developing Custom Differential Privacy Software
The following tools may be useful to researchers and engineers who seek to create customized methods or systems for differentially private analysis:
Chorus (Johnson et al. 2020):149 Originally designed for deployment at Uber, this is a “programming framework for building scalable differential privacy mechanisms” (Johnson et al. 2020), more specifically a “query analysis and rewriting framework to enforce differential privacy for general-purpose SQL queries.”150
Duet (Near et al. 2019):151 Duet is a tool for writing programs that are automatically verified to be differentially private.
Ektelo (Zhang et al. 2018):152 “Ektelo is a programming framework and system that aids programmers in developing differentially private programs with high utility. Ektelo can be used to author programs for a variety of statistical tasks that involve answering counting queries over a table of arbitrary dimension.”153
Fuzzi (Zhang et al. 2019):154 Fuzzi is a programming language for writing programs that can be automatically verified to be differentially private.
LightDP (Zhang and Kifer 2017):155 LightDP is a programming language for writing programs that can be automatically verified to be differentially private.
Machine Learning Software Tools and Repositories
The following are some software tools and projects for differentially private machine learning (especially deep learning) that are both actively developed and publicly available:
Opacus:156 From Facebook, Opacus incorporates differential privacy into PyTorch, which is an “open-source machine learning framework that accelerates the path from research prototyping to production deployment.”157 “It supports training with minimal code changes required on the client, has little impact on training performance and allows the client to online track the privacy budget expended at any given moment.”158
PySyft:159 From OpenMined, “PySyft is a Python library for secure and private Deep Learning. PySyft decouples private data from model training, using Federated Learning, Differential Privacy, and Encrypted Computation (like Multi-Party Computation (MPC) and Homomorphic Encryption (HE)) within the main Deep Learning frameworks like PyTorch and TensorFlow.”160
TensorFlow Privacy (McMahan et al. 2019):161 From Google, this Python library incorporates differential privacy into TensorFlow, an “end-to-end open-source platform for machine learning.”162 The TensorFlow Privacy library “comes with tutorials and analysis tools for computing the privacy guarantees provided.”163
Enterprise Software and Consulting Services
The following are some companies that advertise differentially private solutions:
DataFleets:164 DataFleets offers software for analytics and business intelligence that incorporates differential privacy, secure multiparty computation, and federated learning along with role-based access control and compliance features.
LeapYear:165 LeapYear offers a “platform for differentially private reporting, analytics and machine learning.”166
Oasis Labs:167 Oasis Labs offers privacy tools integrating differential privacy, secure enclaves, distributed ledgers, smart contracts, and federated learning.
Privitar:168 Privitar offers software to “de-identify data, minimize risk and achieve regulatory compliance” while performing “advanced analytics, artificial intelligence, and machine learning.”169
SAP:170 SAP offers a database management system (SAP HANA) that incorporates differential privacy, other forms of anonymization, and security features such as role management and audit logging.
Tumult Labs:171 Tumult Labs builds privacy technology enabling “the safe release of de-identified data, statistics, and machine learning models.”172
Further Reading
There are many educational resources available for readers who have additional questions after reviewing this chapter. Below is a short list of recommended readings, provided in order from least to most technical. Pointers to more resources can also be found on the following web site: https://www.differentialprivacy.org/ (accessed 2020-12-17).
Hector Page, Charlie Cabot, and Kobbi Nissim, Differential Privacy: An Introduction for Statistical Agencies (Page, Cabot, and Nissim 2018).
Alexandra Wood, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, and Salil Vadhan, Differential Privacy: A Primer for a Non-technical Audience (Wood et al. 2018).
Ori Heffetz and Katrina Ligett, Privacy and Data-Based Research (Heffetz and Ligett 2014).
Cynthia Dwork, A Firm Foundation for Private Data Analysis (Dwork 2011).
Cynthia Dwork and Aaron Roth, The Algorithmic Foundations of Differential Privacy (Dwork and Roth 2014).
Gautam Kamath and Jonathan Ullman. A Primer on Private Statistics (Kamath and Ullman 2020).
Salil Vadhan, The Complexity of Differential Privacy (Vadhan 2017).
References
Abadi, Martín, Andy Chu, Ian J. Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. “Deep Learning with Differential Privacy.” In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, October 24-28, 2016, edited by Edgar R. Weippl, Stefan Katzenbeisser, Christopher Kruegel, Andrew C. Myers, and Shai Halevi, 308–18. ACM. https://doi.org/10.1145/2976749.2978318.
Abowd, John. 2019. “Stepping-up: The Census Bureau Tries to Be a Good Data Steward in the 21st Century, Presentation at the Simons Institute for the Theory of Computing.” https://simons.berkeley.edu/talks/tba-30.
Abowd, John, Robert Ashmead, Simson Garfinkel, Dan Kifer, Philip LeClerc, Ashwin Machanavajjhala, Brett Moran, William Sexton, and Pavel Zhuravlev. 2019. “Census TopDown Algorithm: Differentially Private Data, Incremental Schemas, and Consistency with Public Knowledge,” October. https://github.com/uscensusbureau/census2020-das-2010ddp/blob/master/doc/20191020_1843_Consistency_for_Large_Scale_Differentially_Private_Histograms.pdf.
Abowd, John M., and Ian M. Schmutte. 2019. “An Economic Analysis of Privacy Protection and Statistical Accuracy as Social Choices.” American Economic Review 109 (1): 171–202. https://doi.org/10.1257/aer.20170627.
Alabi, Daniel, Audra McMillan, Jayshree Sarathy, Adam Smith, and Salil Vadhan. 2020. “Differentially Private Simple Linear Regression,” July. https://arxiv.org/abs/2007.05157.
Altman, Micah, Alexandra Wood, David R O’Brien, and Urs Gasser. 2018. “Practical Approaches to Big Data Privacy over Time.” International Data Privacy Law 8 (1): 29–51. https://doi.org/10.1093/idpl/ipx027.
Altman, Micah, Alexandra Wood, David O’Brien, Salil Vadhan, and Urs Gasser. 2015. “Towards a Modern Approach to Privacy-Aware Government Data Releases.” Berkeley Technology and Law Journal 1967. https://doi.org/10.2139/ssrn.2779266.
Avent, Brendan, Aleksandra Korolova, David Zeber, Torgeir Hovden, and Benjamin Livshits. 2017. “BLENDER: Enabling Local Search with a Hybrid Differential Privacy Model.” In 26th USENIX Security Symposium, USENIX Security 2017, Vancouver, BC, Canada, August 16-18, 2017, edited by Engin Kirda and Thomas Ristenpart, 747–64. USENIX Association. https://www.usenix.org/conference/usenixsecurity17/technical-sessions/presentation/avent.
Balle, Borja, Gilles Barthe, and Marco Gaboardi. 2018. “Privacy Amplification by Subsampling: Tight Analyses via Couplings and Divergences.” In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montréal, Canada, edited by Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett, 6280–90. http://papers.nips.cc/paper/7865-privacy-amplification-by-subsampling-tight-analyses-via-couplings-and-divergences.
Biemer, Paul P. 2010. “Total Survey Error: Design, Implementation, and Evaluation.” Public Opinion Quarterly 74 (5): 817–48.
Bittau, Andrea, Úlfar Erlingsson, Petros Maniatis, Ilya Mironov, Ananth Raghunathan, David Lie, Mitch Rudominer, Ushasree Kode, Julien Tinnés, and Bernhard Seefeld. 2017. “Prochlo: Strong Privacy for Analytics in the Crowd.” In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, October 28-31, 2017, 441–59. ACM. https://doi.org/10.1145/3132747.3132769.
Blum, Avrim, Cynthia Dwork, Frank McSherry, and Kobbi Nissim. 2005. “Practical Privacy: The SuLQ Framework.” In Proceedings of the Twenty-Fourth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, June 13-15, 2005, Baltimore, Maryland, USA, edited by Chen Li, 128–38. ACM. https://doi.org/10.1145/1065167.1065184.
boyd, danah. 2020. “Balancing Data Utility and Confidentiality in the 2020 US Census.” Data & Society; Data & Society Research Institute. https://datasociety.net/library/balancing-data-utility-and-confidentiality-in-the-2020-us-census/.
Bun, Mark, Jörg Drechsler, Marco Gaboardi, and Audra McMillan. 2020. “Controlling Privacy Loss in Survey Sampling (Working Paper).” CoRR abs/2007.12674. https://arxiv.org/abs/2007.12674.
Bun, Mark, Kobbi Nissim, Uri Stemmer, and Salil Vadhan. 2015. “Differentially Private Release and Learning of Threshold Functions.” IEEE Computer Society, October, 634–49. https://doi.org/10.1109/FOCS.2015.45.
Bureau, US Census. n.d. “Availability of Census Records About Individuals, CFF-2 (June 2008).” https://www.census.gov/history/pdf/cff2.pdf.
Bureau of the Census, Department of Commerce. 2018. “Soliciting Feedback from Users on 2020 Census Data Products.” Federal Register 83 (139). https://www.federalregister.gov/documents/2018/07/19/2018-15458/soliciting-feedback-from-users-on-2020-census-data-products.
Calandrino, Joseph A., Ann Kilzer, Arvind Narayanan, Edward W. Felten, and Vitaly Shmatikov. 2011. “‘You Might Also Like:’ Privacy Risks of Collaborative Filtering.” In 32nd IEEE Symposium on Security and Privacy, S&P 2011, 22-25 May 2011, Berkeley, California, USA, 231–46. IEEE Computer Society. https://doi.org/10.1109/SP.2011.40.
Chetty, Raj, and John N. Friedman. 2019. “A Practical Method to Reduce Privacy Loss When Disclosing Statistics Based on Small Samples.” Journal of Privacy and Confidentiality 9 (2). https://doi.org/10.29012/jpc.716.
Chetty, Raj, John N. Friedman, Nathaniel Hendren, Maggie R. Jones, and Sonya R. Porter. 2018. “The Opportunity Atlas: Mapping the Childhood Roots of Social Mobility.” Working Paper 25147. National Bureau of Economic Research. https://doi.org/10.3386/w25147.
Cheu, Albert, Adam D. Smith, Jonathan Ullman, David Zeber, and Maxim Zhilyaev. 2019. “Distributed Differential Privacy via Shuffling.” In Advances in Cryptology - EUROCRYPT 2019 - 38th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Darmstadt, Germany, May 19-23, 2019, Proceedings, Part I, edited by Yuval Ishai and Vincent Rijmen, 11476:375–403. Lecture Notes in Computer Science. Springer. https://doi.org/10.1007/978-3-030-17653-2\_13.
Crosas, Mercè. 2011. “The Dataverse Network: An Open-Source Application for Sharing, Discovering and Preserving Data.” D-Lib Magazine 17 (1): 2. https://doi.org/10.1045/january2011-crosas.
Crosas, Mercè. 2013. “A Data Sharing Story.” Journal of eScience Librarianship 1 (3): 7. https://doi.org/10.7191/jeslib.2012.1020.
de Montjoye, Yves-Alexandre, César A. Hidalgo, Michel Verleysen, and Vincent D. Blondel. 2013. “Unique in the Crowd: The Privacy Bounds of Human Mobility.” Scientific Reports 3 (1): 1376. https://doi.org/10.1038/srep01376.
Desai, Tanvi, Felix Ritchie, and Richard Welpton. 2016. “Five Safes: Designing Data Access for Research.” University of the West of England. https://uwe-repository.worktribe.com/output/914745.
Differential Privacy Team, Apple. 2017. “Learning with Privacy at Scale,” December. https://machinelearning.apple.com/research/learning-with-privacy-at-scale.
Ding, Bolin, Janardhan Kulkarni, and Sergey Yekhanin. 2017. “Collecting Telemetry Data Privately.” In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4-9 December 2017, Long Beach, CA, USA, edited by Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, 3571–80. http://papers.nips.cc/paper/6948-collecting-telemetry-data-privately.
Dinur, Irit, and Kobbi Nissim. 2003. “Revealing Information While Preserving Privacy.” In Proceedings of the Twenty-Second ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, June 9-12, 2003, San Diego, CA, USA, edited by Frank Neven, Catriel Beeri, and Tova Milo, 202–10. ACM. https://doi.org/10.1145/773153.773173.
Dwork, Cynthia. 2011. “A Firm Foundation for Private Data Analysis.” Communications of the ACM 54 (1): 86–95. https://doi.org/10.1145/1866739.1866758.
Dwork, Cynthia, Nitin Kohli, and Deirdre Mulligan. 2019. “Differential Privacy in Practice: Expose Your Epsilons!” Journal of Privacy and Confidentiality 9 (2). https://doi.org/10.29012/jpc.689.
Dwork, Cynthia, Frank McSherry, Kobbi Nissim, and Adam D. Smith. 2016. “Calibrating Noise to Sensitivity in Private Data Analysis.” Journal of Privacy and Confidentiality 7 (3): 17–51. https://doi.org/10.29012/jpc.v7i3.405.
Dwork, Cynthia, and Aaron Roth. 2014. “The Algorithmic Foundations of Differential Privacy.” Foundations and Trends in Theoretical Computer Science 9 (3-4): 211–407. https://doi.org/10.1561/0400000042.
Dwork, Cynthia, Adam Smith, Thomas Steinke, and Jonathan Ullman. 2017. “Exposed! A Survey of Attacks on Private Data.” Annual Review of Statistics and Its Application 4 (1): 61–84. https://doi.org/10.1146/annurev-statistics-060116-054123.
Erlingsson, Úlfar, Vasyl Pihur, and Aleksandra Korolova. 2014. “RAPPOR: Randomized Aggregatable Privacy-Preserving Ordinal Response.” Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security - CCS ’14, 1054–67. https://doi.org/10.1145/2660267.2660348.
Fluitt, Aaron, Aloni Cohen, Micah Altman, Kobbi Nissim, Salome Viljoen, and Alexandra Wood. 2019. “Data Protection’s Composition Problem.” European Data Protection Law Review 5 (3). https://doi.org/10.21552/edpl/2019/3/4.
Foote, Andrew David, Ashwin Machanavajjhala, and Kevin McKinney. 2019. “Releasing Earnings Distributions Using Differential Privacy: Disclosure Avoidance System for Post-Secondary Employment Outcomes (PSEO).” Journal of Privacy and Confidentiality 9 (2). https://doi.org/10.29012/jpc.722.
Gaboardi, Marco, James Honaker, Gary King, Kobbi Nissim, Jonathan Ullman, and Salil P. Vadhan. 2016. “PSI (\(\psi\)): A Private Data Sharing Interface.” CoRR abs/1609.04340. http://arxiv.org/abs/1609.04340.
Ganta, Srivatsava Ranjit, Shiva Prasad Kasiviswanathan, and Adam D. Smith. 2008. “Composition Attacks and Auxiliary Information in Data Privacy.” In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, Nevada, USA, August 24-27, 2008, edited by Ying Li, Bing Liu, and Sunita Sarawagi, 265–73. ACM. https://doi.org/10.1145/1401890.1401926.
Garfinkel, Simson L. 2017. “Modernizing Disclosure Avoidance: Report on the 2020 Disclosure Avoidance Subsystem as Implemented for the 2018 End-to-End Test (Continued),” September. https://www2.census.gov/cac/sac/meetings/2017-09/garfinkel-modernizing-disclosure-avoidance.pdf.
Garfinkel, Simson L., John M. Abowd, and Christian Martindale. 2019. “Understanding Database Reconstruction Attacks on Public Data.” Communications of the ACM 62 (3): 46–53. https://doi.org/10.1145/3287287.
Garfinkel, Simson L., John M. Abowd, and Sarah Powazek. 2018. “Issues Encountered Deploying Differential Privacy.” In Proceedings of the 2018 Workshop on Privacy in the Electronic Society, 133–37. WPES’18. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3267323.3268949.
Ge, Chang, Xi He, Ihab F. Ilyas, and Ashwin Machanavajjhala. 2019. “APEx: Accuracy-aware Differentially Private Data Exploration.” In Proceedings of the 2019 International Conference on Management of Data, 177–94. SIGMOD ’19. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3299869.3300092.
Haeberlen, Andreas, Benjamin C. Pierce, and Arjun Narayan. 2011. “Differential Privacy Under Fire.” In Proceedings of the 20th USENIX Security Symposium.
Hawes, Michael B. 2020. “Implementing Differential Privacy: Seven Lessons from the 2020 United States Census.” Harvard Data Science Review 2 (2). https://doi.org/10.1162/99608f92.353c6f99.
Heffetz, Ori, and Katrina Ligett. 2014. “Privacy and Data-Based Research.” Journal of Economic Perspectives, Working paper series, 28 (2): 75–98. https://doi.org/10.3386/w19433.
Higgins, Sarah. 2008. “The DCC Curation Lifecycle Model.” International Journal of Digital Curation 3 (1).
Holohan, Naoise, Stefano Braghin, Pól Mac Aonghusa, and Killian Levacher. 2019. “Diffprivlib: The IBM Differential Privacy Library.” http://arxiv.org/abs/1907.02444.
Johnson, Noah, Joseph P. Near, Joseph M. Hellerstein, and Dawn Song. 2020. “CHORUS: A Programming Framework for Building Scalable Differentially Private Mechanisms.” In Proceedings of the 2020 IEEE European Symposium on Security and Privacy (EUroS&P). IEEE.
Kamath, Gautam, and Jonathan Ullman. 2020. “A Primer on Private Statistics.” http://arxiv.org/abs/2005.00010.
Kasiviswanathan, Shiva Prasad, Homin K. Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam D. Smith. 2011. “What Can We Learn Privately?” SIAM Journal on Computing 40 (3): 793–826. https://doi.org/10.1137/090756090.
King, Gary. 2007. “An Introduction to the Dataverse Network as an Infrastructure for Data Sharing.” Sociological Methods & Research 36 (2): 173–99. https://doi.org/10.1177/0049124107306660.
King, Gary. 2014. “Restructuring the Social Sciences: Reflections from Harvard’s Institute for Quantitative Social Science.” PS: Political Science & Politics 47 (1): 165–72. https://doi.org/10.1017/S1049096513001534.
Krishnan, Sanjay, Jiannan Wang, Michael J. Franklin, Ken Goldberg, and Tim Kraska. 2016. “PrivateClean: Data Cleaning and Differential Privacy.” In Proceedings of the 2016 International Conference on Management of Data, 937–51. SIGMOD ’16. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/2882903.2915248.
McMahan, H. Brendan, Galen Andrew, Ulfar Erlingsson, Steve Chien, Ilya Mironov, Nicolas Papernot, and Peter Kairouz. 2019. “A General Approach to Adding Differential Privacy to Iterative Training Procedures.” Proceedings of NeurIPS ’18 Workshop on Privacy Preserving Machine Learning (PPML), December 2018, Montreal, Canada. https://arxiv.org/abs/1812.06210.
Mironov, Ilya. 2012. “On Significance of the Least Significant Bits for Differential Privacy.” In Proceedings of the 2012 ACM Conference on Computer and Communications Security, 650–61. https://doi.org/10.1145/2382196.2382264.
Narayanan, Arvind, and Vitaly Shmatikov. 2008. “Robust de-Anonymization of Large Sparse Datasets.” In 2008 IEEE Symposium on Security and Privacy (S&P 2008), 18-21 May 2008, Oakland, California, USA, 111–25. IEEE Computer Society. https://doi.org/10.1109/SP.2008.33.
Near, Joseph P., David Darais, Chike Abuah, Tim Stevens, Pranav Gaddamadugu, Lun Wang, Neel Somani, et al. 2019. “Duet: An Expressive Higher-Order Language and Linear Type System for Statically Enforcing Differential Privacy.” Proc. ACM Program. Lang. 3 (OOPSLA). https://doi.org/10.1145/3360598.
Nissim, Kobbi, Aaron Bembenek, Alexandra Wood, Mark Bun, Marco Gaboardi, Urs Gasser, David R O’Brien, Thomas Steinke, and Salil Vadhan. 2018. “Bridging the Gap Between Computer Science and Legal Approaches to Privacy.” Harvard Journal of Law & Technology 31 (2): 687–780. https://privacytools.seas.harvard.edu/publications/bridging-gap-between-computer-science-and-legal-approaches-privacy.
Page, Hector, Charlie Cabot, and Kobbi Nissim. 2018. “Differential Privacy: An Introduction for Statistical Agencies, a Contributing Article to the National Statistician’s Quality Review into Privacy and Data Confidentiality Methods, UK Office for National Statistics.” https://gss.civilservice.gov.uk/wp-content/uploads/2018/12/12-12-18FINALPrivitarKobbiNissimarticle.pdf.
Ramachandran, Aditi, Lisa Singh, Edward Porter, and Frank Nagle. 2012. “Exploring Re-Identification Risks in Public Domains.” In 2012 Tenth Annual International Conference on Privacy, Security and Trust, 35–42. https://doi.org/10.1109/PST.2012.6297917.
Reich, Victoria, and David Rosenthal. 2009. “Distributed Digital Preservation: Private LOCKSS Networks as Business, Social, and Technical Frameworks.” Library Trends 57 (3): 461–75.
Rosenthal, David SH, Thomas S Robertson, Tom Lipkis, Vicky Reich, and Seth Morabito. 2005. “Requirements for Digital Preservation Systems: A Bottom-up Approach.” D-Lib Magazine 11 (11): 1082–9873.
Stemmer, Uri, and Haim Kaplan. 2018. “Differentially Private K-Means with Constant Multiplicative Error.” In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, 3-8 December 2018, Montréal, Canada, edited by Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett, 5436–46. http://papers.nips.cc/paper/7788-differentially-private-k-means-with-constant-multiplicative-error.
Sweeney, Latanya. 1997. “Weaving Technology and Policy Together to Maintain Confidentiality.” The Journal of Law, Medicine & Ethics 25 (2-3): 98–110. https://doi.org/10.1111/j.1748-720X.1997.tb01885.x.
Thaker, Pratiksha, Mihai Budiu, Parikshit Gopalan, Udi Wieder, and Matei Zaharia. 2020. “Overlook: Differentially Private Exploratory Visualization for Big Data.” https://arxiv.org/abs/2006.12018.
The OpenDP Team. 2020. “The OpenDP White Paper,” May. https://projects.iq.harvard.edu/files/opendp/files/opendp_white_paper_11may2020.pdf.
US Census Bureau Center for Economic Studies. n.d. “US Census Bureau Center for Economic Studies Publications and Reports Page.” Accessed December 16, 2020. https://lehd.ces.census.gov/data/pseo_experimental.html.
Vadhan, Salil. 2017. “The Complexity of Differential Privacy.” In Tutorials on the Foundations of Cryptography, edited by Yehuda Lindell, 347–450. Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-57048-8_7.
Wang, Yu-Xiang. 2018. “Revisiting Differentially Private Linear Regression: Optimal and Adaptive Prediction & Estimation in Unbounded Domain.” In Proceedings of the Thirty-Fourth Conference on Uncertainty in Artificial Intelligence, UAI 2018, Monterey, California, USA, August 6-10, 2018, edited by Amir Globerson and Ricardo Silva, 93–103. AUAI Press. http://auai.org/uai2018/proceedings/papers/40.pdf.
Willenborg, Leon, and Ton De Waal. 1996. Statistical Disclosure Control in Practice. Vol. 111. Springer Science & Business Media.
Wilson, Royce J., Celia Yuxin Zhang, William Lam, Damien Desfontaines, Daniel Simmons-Marengo, and Bryant Gipson. 2020. “Differentially Private SQL with Bounded User Contribution.” In Proceedings on Privacy Enhancing Technologies, 2:230–50.
Wood, Alexandra, Micah Altman, Aaron Bembenek, Mark Bun, Marco Gaboardi, James Honaker, Kobbi Nissim, David R. O’Brien, Thomas Steinke, and Salil Vadhan. 2018. “Differential Privacy: A Primer for a Non-Technical Audience.” Vanderbilt Journal of Entertainment and Technology Law 21 (1). http://www.jetlaw.org/journal-archives/volume-21/volume-21-issue-1/differential-privacy-a-primer-for-a-non-technical-audience/.
Zhang, Danfeng, and Daniel Kifer. 2017. “LightDP: Towards Automating Differential Privacy Proofs.” In Proceedings of the 44th ACM SIGPLAN Symposium on Principles of Programming Languages, 888–901. POPL 2017. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3009837.3009884.
Zhang, Dan, Ryan McKenna, Ios Kotsogiannis, Michael Hay, Ashwin Machanavajjhala, and Gerome Miklau. 2018. “EKTELO: A Framework for Defining Differentially-Private Computations.” In Proceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018, edited by Gautam Das, Christopher M. Jermaine, and Philip A. Bernstein, 115–30. ACM. https://doi.org/10.1145/3183713.3196921.
Zhang, Hengchu, Edo Roth, Andreas Haeberlen, Benjamin C. Pierce, and Aaron Roth. 2019. “Fuzzi: A Three-Level Logic for Differential Privacy.” Proc. ACM Program. Lang. 3 (ICFP). https://doi.org/10.1145/3341697.
For an overview of traditional SDL techniques, see Harris-Kojetin et al. (2005) and chapter 5 in this Handbook.↩︎
For an introduction to de-identification techniques, see Garfinkel (2016).↩︎
See, e.g., Chapter 2 Section 25 of the Thirteenth Census Act (The Statutes at Large of the United States of America 1909).↩︎
Note that the fact that small risks can combine dramatically is a key insight essential to differential privacy. Differential privacy provides a quantification of privacy risk, and provable guarantees with respect to the cumulative risk from successive data releases. Some risk assessment frameworks, such as the Five Safes framework as originally proposed, make an assumption that “many research outputs pose no disclosure risk because of their functional form” (Desai, Ritchie, and Welpton 2016, pg. 13). Traditional disclosure avoidance methods do not provide ways to quantify the accumulation of privacy risk from multiple uses and releases of data.↩︎
See Ganta, Kasiviswanathan, and Smith (2008). The impression that these techniques do not suffer accumulated degradation in privacy is merely due to the fact that these techniques have not been analyzed with the high degree of rigor that has been applied to differential privacy. For a discussion of privacy and utility with respect to traditional statistical disclosure limitation techniques, see Chen et al. (2009).↩︎
As an example, in 2006 AOL published anonymized search histories of 650,000 users over a period of three months. Shortly after the release, the New York Times identified a person in the release and AOL removed the data from their site. However, in spite of the withdrawal by AOL, copies of the data are still accessible on the Internet today.↩︎
The authors distinguish protection against privacy attacks, which involves the attacker making use of the intended “advertised” functionality of a data access mechanism, from protection against security attacks, which involves an attacker attempting to exploit unintended implementation vulnerabilities (e.g., by circumventing access control mechanisms). Differential privacy does not generally provide protection against security attacks, which should be addressed using complementary controls like encryption and access control.↩︎
For an example of an analysis of this relationship with respect to the Family Educational Rights and Privacy Act’s (FERPA) definition of PII, see Nissim et al. (2018).↩︎
The choice of noise addition technique—whether statistical noise is used to blur individual data points, the output of a computation, or intermediate computations—is a delicate algorithmic question; a variety of noise addition techniques have been developed for differentially private analysis with the purpose of guaranteeing differential privacy while minimizing the overall inaccuracy introduced.↩︎
For data over an ordered domain, a cumulative distribution function depicts for every value x an estimate of the number of data points with a value up to x. For a more in-depth discussion of differential privacy and CDFs, see Muise and Nissim (2016).↩︎
See, for example, Blum, Ligett, and Roth (2013). Synthetic data are data sets generated from a statistical model estimated using the original data. The records in a synthetic data set have no one-to-one correspondence with the individuals in the original data set, yet the synthetic data can retain many of the statistical properties of the original data. Synthetic data resemble the original sensitive data in format and, for a large class of analyses, results are similar whether performed on the synthetic or original data.↩︎
Intuitively, preserving more statistical information (e.g., all entries of a high-dimensional variance-covariance matrix) requires spreading the privacy-loss budget more thinly and thus introducing greater noise. There are much more complex methods that can detect and exploit relationships between the statistics to introduce less noise, but those methods can be computationally infeasible on high-dimensional data.↩︎
The use of differentially private analysis is not equivalent to the traditional use of opting out. On the privacy side, differential privacy does not require an explicit opt-out. In comparison, traditional use of opt-out requires an explicit choice that may cause privacy harms by calling attention to individuals that choose to opt out. On the utility side, there is no general expectation that using differential privacy would yield the same outcomes as adopting the policy of opt-out.↩︎
This insight follows from a series of papers demonstrating privacy breaches enabled by leakages of information resulting from decisions made by the computation. See, for example, Kenthapadi, Mishra, and Nissim (2013). For a general discussion of the advantages of formal privacy models over ad hoc privacy techniques, see Narayanan, Huey, and Felten (2016).↩︎
One might object that the student’s GPA is not traceable back to that student unless an observer knows how the statistic was produced. However, a basic principle of modern cryptography (known as Kerckhoffs’ principle) is that a system is not secure if its security depends on its inner workings being a secret. In this context, it is assumed that the algorithm behind a statistical analysis is public (or could potentially become public).↩︎
In other differentially private computations noise may be added to intermediate results of a computation or at the data collection process. The latter is referred to as the local model of differential privacy.↩︎
\(\varepsilon\) is a unitless nonnegative quantity measuring probability log-ratio.↩︎
In general, setting ε involves making a compromise between privacy protection and accuracy. The consideration of both utility and privacy is challenging in practice and, in some of the early implementations of differential privacy, has led to choosing a higher value for \(\varepsilon\). As the accuracy of differentially private analyses improves over time, it is likely that lower values of \(\varepsilon\) will be chosen.↩︎
Figures in this example are based on data from US Social Security Administration (2011).↩︎
The approximate calculation provided in this example only holds for small, using \(\varepsilon\), using \(e^{2\cdot \varepsilon}\approx 1+2\cdot \varepsilon\). See Table 6.1 for an exact formula.↩︎
In general, the guarantee made by differential privacy is that the probabilities differ at most by a factor of \(e^{\pm\varepsilon}\), which is approximately \(1\pm\varepsilon\) when \(\varepsilon\) is small.↩︎
The reason that the multiplicative factor is \(1+2\cdot \varepsilon \approx e^{2\cdot \varepsilon}\) rather than \(1+\varepsilon \approx e^\varepsilon\) is that posterior beliefs can be expressed as a ratio of two probabilities, each of which can change by a factor of at most \(e^{\varepsilon}\). The factor of 2 was incorrectly omitted in the original paper (Wood et al. 2018) describing this example.↩︎
Table 6.1 corrects a calculation error appearing in the original paper (Wood et al. 2018).↩︎
For further discussion see Wood et al. (2018); Altman et al. (2015).↩︎
See Section 6.2.3 for further discussion of how ε quantifies privacy risk.↩︎
The proposal for an Epsilon Registry is intended to be a publicly available bulletin board where firms would disclose information about their deployment of differential privacy. See Dwork, Kohli, and Mulligan (2019).↩︎
In this framework, evaluating the intended uses of the data involves an assessment of the types of uses or analytic purposes intended by each of the relevant groups of data users and how privacy controls implemented at each stage enable or restrict such uses. An evaluation of the threats involves assessing potential adverse circumstances or events that could cause harm to a data subject as a result of the inclusion of that subject’s data in a specific data collection, storage, use, or release. Privacy harms are injuries sustained by data subjects as a result of the realization of a privacy threat, and privacy vulnerabilities are defined as characteristics that increase the likelihood that threats will be realized. See Altman et al. (2015).↩︎
See, e.g., Google’s COVID-19 Community Mobility Reports (Aktay et al. 2020), https://www.google.com/covid19/mobility (accessed 2020-12-17).↩︎
For an extended discussion and framework for assessing information sensitivity, see Altman et al. (2015).↩︎
See, e.g., Regulation (EU) 2016/679 of the European Parliament and of the Council on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (2016) OJ L119/1, Article 9 (providing that the “[p]rocessing of personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade union membership, and the processing of genetic data, biometric data for the purpose of uniquely identifying a natural person, data concerning health or data concerning a natural person’s sex life or sexual orientation shall be prohibited,” unless one of the delineated exceptions in Paragraph 2 of the Article applies).↩︎
See, e.g., “Harvard University Information Security, Handout—Research Data Security Levels with Examples,” https://security.harvard.edu/handout-research-data-security-levels-examples (accessed 2020-12-17).↩︎
For discussions of how data privacy risks accumulate, see Altman et al. (2018); Fluitt et al. (2019).↩︎
Note that the reference to “using an individual’s data” in this statement means the inclusion of an individual’s data in an analysis, and the use of the term “specific” refers to information that is unique to the individual and cannot be inferred unless the individual’s information is used in the analysis. Furthermore, the use of the word “essential” in the statement “will not reveal essentially any PII specific to them” means that, compared with an opt-out scenario where no information specific to an individual is leaked, some small leakage of such information (inevitably) occurs. The parameter ε bounds this leakage.↩︎
For an extended discussion of the gaps between legal and computer science definitions of privacy and a demonstration that differential privacy can be used to satisfy an institution’s obligations under FERPA, see Nissim et al. (2018).↩︎
Specifically, the US Constitution mandates the Decennial Census (U.S. Const. art. 1, 2.), and it is carried out by the US Census Bureau, bound by Title 13 of the US Code, which prohibits Census Bureau employees from “mak[ing] any publication whereby the data furnished by any particular establishment or individual under this title can be identified” (13 U.S.C. § 9(a)(2), accessed 2020-12-17).↩︎
See United States Census Bureau, 2020 Disclosure Avoidance System Updates (accessed 2020-12-17).↩︎
The raw data from the Census Bureau is protected by Title 13 of the United States Code, which prohibits “mak[ing] any publication whereby the data furnished by any particular establishment or individual under this title can be identified” (13 U.S.C. § 9(a)(2), accessed 2020-12-17). Pursuant to Title 26, the IRS shares federal tax returns and return information with the Census Bureau for statistical purposes, and the Census Bureau is prohibited from disclosing such tax return information except in “a form which cannot be associated with, or otherwise identify, directly or indirectly, a particular taxpayer” (26 U.S.C. 6103(j)(4), accessed 2020-12-17).↩︎
Harvard University Privacy Tools Project, http://privacytools.seas.harvard.edu (accessed 2020-12-17).↩︎
OpenDP, http://opendp.io/ (accessed 2020-12-17).↩︎
In the earlier sections, the simplest formulation of differential privacy have been presented in which a data set is a collection of records, each about an individual data subject, and the requirement is that for any two data sets that differ on one record, the output distributions are close within a factor of 1+\(\varepsilon\). However, the theory and practice of differential privacy include extensions well beyond this basic formulation.↩︎
For example, while protection of individual purchases would hide whether gluten-free bread was bought in a specific purchase, it may still reveal that the purchaser mostly buys gluten-free bread.↩︎
Measurement design in this sense and in this section refers to the development or selection of procedures to measure a characteristic (often a latent construct) of a unit of observation that is related to a concept of interest to the research goal. See, e.g., Robert M Groves et al. (2011).↩︎
See, however, Vayena et al. (2015); Altman et al. (2018) with respect to ethical limitation of consent in the context of big data, even when differential privacy protects against individual identification.↩︎
For a discussion of the privacy and utility considerations to consider when setting epsilon and the recommended starting point of 0.1, see Wood et al. (2018).↩︎
As one example of such an analysis, see Nissim et al. (2018) that argues the use of differential privacy is sufficient to satisfy the requirements of the Family Educational Rights and Privacy Act of 1974.↩︎
Complementary controls may still be needed, particularly in cases in which the data are very sensitive as shown in Figure 6.4 and described in Altman et al. (2015).↩︎
The interactive interface increases the total cost of ownership, as it must be maintained by the controller for the useful life of the data. This contrasts with static data publication in which data publication can be replicated across users, and the computations are performed (and paid for) by users.↩︎
Roughly speaking, a privacy-protecting method is truthful if one can determine unambiguously which types of statements, when semantically correct as applied to the protected data, are also semantically correct when applied to the original sample data. For instance, synthetic data does not generally support truthful claims about individual records in the data but supports some truthful claims about the population from which the data are drawn. In contrast, methods involving local suppression support some truthful claims about records, but generally do not yield truthful/unbiased claims about population statistics. See Wood et al. (2018).↩︎
For a summary of these concepts and a discussion of their interaction with data privacy, see Sciences et al. (2016).↩︎
Further, data, once released to uncontrolled actors, cannot realistically be disposed. If disposal of privacy-protected data is required, then release of synthetic data or data collected via the local model must still be managed.↩︎
Diffprivlib, https://www.github.com/IBM/differential-privacy-library (accessed 2020-12-17).↩︎
Id.↩︎
Id.↩︎
Google Differential Privacy Library, https://www.github.com/google/differential-privacy (accessed 2020-12-17).↩︎
Id.↩︎
Id.↩︎
NIST Privacy Engineering Collaboration Space, https://www.nist.gov/itl/applied-cybersecurity/privacy-engineering/collaboration-space (accessed 2020-12-17).↩︎
Id.↩︎
OpenDP, http://opendp.org (accessed 2020-12-17).↩︎
OpenMined, http://www.openmined.org (accessed 2020-12-17).↩︎
Id.↩︎
PyDP, https://github.com/OpenMined/PyDP (accessed 2020-12-17).↩︎
Hillview for differentially-private visualizations, https://github.com/vmware/hillview/blob/master/privacy.md (accessed 2020-12-17).↩︎
Hillview, https://github.com/vmware/hillview (accessed 2020-12-17).↩︎
Chorus repository,↩︎
Original (now deprecated) Chorus repository, https://github.com/uber-archive/sql-differential-privacy (accessed 2020-12-17).↩︎
Duet, https://github.com/uvm-plaid/duet (accessed 2020-12-17).↩︎
Ektelo repository, http://ektelo.github.io (accessed 2020-12-17).↩︎
Id.↩︎
Fuzzi repository, https://github.com/hengchu/fuzzi-impl (accessed 2020-12-17).↩︎
LightDP, https://github.com/yxwangcs/lightdp (accessed 2020-12-17).↩︎
Opacus, https://www.github.com/pytorch/opacus (accessed 2020-12-17). See also Facebook AI, Introducing Opacus: A high-speed library for training PyTorch models with differential privacy, Blog post (Aug. 31, 2020), https://ai.facebook.com/blog/introducing-opacus-a-high-speed-library-for-training-pytorch-models-with-differential-privacy (accessed 2020-12-17).↩︎
PyTorch, https://www.pytorch.org (accessed 2020-12-17).↩︎
Opacus, https://www.github.com/pytorch/opacus (accessed 2020-12-17).↩︎
PySyft, https://www.github.com/OpenMined/PySyft (accessed 2020-12-17).↩︎
Id.↩︎
TensorFlow Privacy, https://www.github.com/tensorflow/privacy (accessed 2020-12-17).↩︎
TensorFlow, https://www.tensorflow.org (accessed 2020-12-17).↩︎
TensorFlow Privacy, https://www.github.com/tensorflow/privacy (accessed 2020-12-17).↩︎
DataFleets, https://www.datafleets.com (accessed 2020-12-17).↩︎
LeapYear, https://www.leapyear.io (accessed 2020-12-17).↩︎
Id.↩︎
Oasis Labs, http://www.oasislabs.com (accessed 2020-12-17).↩︎
Privitar, https://www.privitar.com (accessed 2020-12-17).↩︎
Id.↩︎
SAP HANA Data Anonymization, https://www.sap.com/cmp/dg/crm-xt17-ddm-data-anony/index.html (accessed 2020-12-17).↩︎
Tumult Labs, https://www.tmlt.io (accessed 2020-12-17).↩︎
Id.↩︎